General
Q: What are Designer, Deployment Management, Runtime and Workflow Orchestration?
They are the main platform modules of Agile Data Engine. See Key Concepts and Architecture for more information.
Q: What are metadata database locks?
Agile Data Engine acquires internal entity locks for entities being processed. Suppose a situation where a deployment is processing an entity when a load is started against the same entity. In this situation, the deployment has the lock and the load has to wait until the deployment is ready and the lock is released. When the lock is released, the load acquires the lock and starts processing.
Also see: Can I see the acquired locks from somewhere?
Q: Can I see the acquired locks from somewhere?
Active locks are listed in the Active object locks dashboard in the Dashboards view (Grafana) of each Runtime environment.
Q: Can an external API be called from Agile Data Engine?
Not directly, but you can call stored procedures and external functions in the target database from load steps. Also the Notification Events feature can be used to trigger external actions.
Q: Why ADE has chosen a trunk-based development approach over a feature branching approach?
Agile Data Engine uses a trunk-based development approach where everyone works with the same master branch and makes small, frequent changes directly to it. This approach is chosen to enable:
-
Rapid iteration and deployment: Trunk-based development encourages frequent commits to the main branch. This can lead to faster development cycles and quicker delivery of new features or changes to production.
-
Simplified Development Workflow: Developers work directly on the main branch, reducing complexity and potential merge conflicts.
-
Continuous Integration (CI): Trunk-based development is well-suited for continuous integration practices. With every commit to the main branch, automated tests can be run, ensuring that code quality is maintained throughout development.
-
Early Feedback and Testing: Changes are integrated into the main branch early and often. This allows for early testing and feedback, helping to identify and address issues sooner in the development process.
-
Easier Collaboration: Trunk-based development encourages collaboration among team members. Developers are more likely to work together on the same codebase, which can foster knowledge sharing and code reviews.
Q: How does trunk-based development approach work in ADE?
Introduction
The ADE service offers a web-based graphical user interface accessible to all users within the same ADE tenant. This user interface is designed to provide real-time updates, ensuring that all developers and development teams work with the most current version. This collaborative environment fosters transparency, allowing users to track each other's activities seamlessly.
Unified Collaboration on the Master Branch
In ADE, a fundamental principle is the adoption of a single "master branch" for development. This means that all developers actively contribute to the same branch directly through the user interface. While it might appear as a singular approach, it has been carefully designed to enhance efficiency and collaboration.
Package-Based Development
To enable multiple developers to work harmoniously within the same "master branch," the development process is organized into smaller, manageable units called "packages." Each package serves as a container for entities and their incoming loads, representing the deployable unit in our development workflow.
Version Control and Comparability
When a package is committed and deployed within ADE, it is assigned a unique version number. This versioning system creates a historical record of the package's evolution, enabling developers to easily track changes over time. The ability to compare different package versions enhances the understanding of progress.
Furthermore, this version control mechanism empowers developers with the flexibility to restore older package versions when needed. This capability provides a safety net, ensuring that, at some level, prior configurations can be reinstated. It's a powerful feature for troubleshooting, rollbacks, and maintaining data integrity.
Designer
Q: What is a package?
A package is a container for entities, and the unit for committing, promoting and deploying changes in Agile Data Engine. This means that deployment is done on package level and all the entities and loads inside the package are deployed. See Key Concepts and Architecture and packages for more information.
Q: What is an entity?
Entities are fundamental metadata objects in Agile Data Engine that can represent data warehouse objects such as tables, views and materialized views, or metadata (METADATA_ONLY). See Key Concepts and Architecture and entities for more information.
Q: What is a load?
Loads are part of entities and they define load transformations, entity mappings and smoke tests. See Key Concepts and Architecture and loads for more information.
Q: What is a schedule and how does it relate to workflows (DAGs)?
A schedule is used to group loads and to further build workflows. A schedule may also define when a workflow starts. One workflow (DAG) is created for each schedule that is connected to at least one load. All loads with the same, inherited or explicit, schedule are included into the same workflow. The order of loads in a workflow is based on entity dependencies defined in entity mappings. See Key Concepts and Architecture, Designing Workflows, CONFIG_LOAD_SCHEDULES and Workflow Orchestration for more information.
Q: Why is it that some loads have a defined schedule in the Designer and some do not?
Quite often a schedule is explicitly set in the Designer only for the first load(s) of a workflow. Usually the first load is a file load into a staging table. After that all the loads of dependent entities are automatically placed in that schedule unless overwritten by a manual schedule selection. That way a load can be placed in several schedules and to several workflows. See Designing Workflows for more information.
Q: How can I find an entity, attribute, load etc. from the Designer?
Search is located at the top right of the main page:
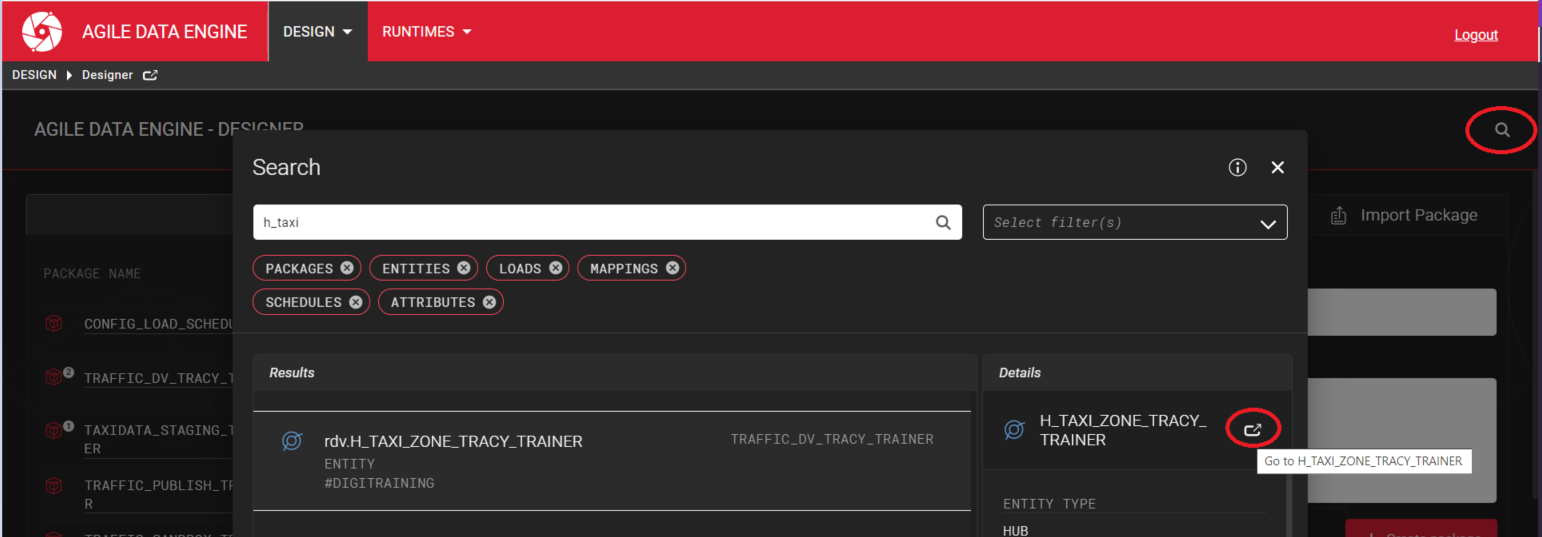
After you have found what you are looking for press the Go to button.
Q: I need to split a package and move entities to another package. How can I do that?
Create a new package if it is not created already. After that use the Move to another package feature.
Q: Why do I need to add entity mappings if I use override queries?
Entity mappings ensure that loads are placed in the correct order into workflows so that loads of dependent entities are executed first. By mapping entities and attributes you also avoid manual creation of the attributes. Furthermore, mappings can be useful as metadata for data lineage, data catalogues etc.
Deployment Management
Q: Deployment fails with ERROR: NULL result in a non-nullable column error. What does it mean?
This error occurs when trying to add a non-nullable column to a table that already contains data. When a table contains data the new column gets a NULL value that is not allowed in this case. To resolve the situation you can, for example, remove the NOT NULL constraint, use a default value or delete the rows from the table (you may need to load the data again anyway).
Q: Oh no, I dropped an entity directly from a database manually and now a deployment fails. What should I do?
Agile Data Engine does not know if an entity is dropped from a database by someone else or by some other process. This is because Agile Data Engine relates to its saved state which is not checked from the database before deployments. I.e. SQL statements that Agile Data Engine runs in the target database may fail if the entities have been manipulated by some other process. This causes the target database to throw an error and the deployment to fail.
To resolve the situation, the dropped entity can be recreated manually:
-
Copy the CREATE statement from the Designer; Select the entity from Designer and in a Summary tab press Export SQL.
-
Run the CREATE statement in the database.
-
Grant the required privileges on the entity to the role that Agile Data Engine uses to ensure that Agile data Engine can update the entity.
Q: Error: Scheduling id xxx is not recognized in load_yyy
You have not promoted a version of the CONFIG_LOAD_SCHEDULES package that contains the missing schedule to the Runtime environment in question.
Workflow Orchestration
Q: What is a DAG?
Q: What is a workflow?
Workflows, also known as DAGs, contain loads that are orchestrated in a sequence defined by entity mappings, DAG generation mode and CONFIG_LOAD_SCHEDULES. See Key Concepts and Architecture, Designing Workflows and Workflow Orchestration page for more information.
Q: What are pools and slots in Workflow Orchestration?
Tasks such as loads are run in pools. The number of slots in a pool defines how many concurrent tasks can be run at the same time. See Pools for more information.
To see the pools and slots go to Workflow Orchestration and select Admin and Pools. Below 3/4 slots are being used and no slots are waiting in a queue:

Q: I can't find a DAG from Workflow Orchestration. What could cause this?
Check that you have committed and deployed the related packages. If you have, a common reason is a failed deployment in Deployment Management. Check if the deployment logs have errors and fix them. If the deployment has been successful, check that the corresponding schedule is selected for the first load of the workflow. See Why is it that some loads have a defined schedule in the Designer and some do not? and Workflow Orchestration for more information.
Q: I can't find a load from Workflow Orchestration. How to fix this?
See I can't find a DAG from Workflow Orchestration. What could cause this? If the answer does not resolve the issue, check that you have added an entity mapping to the load you cannot find.
Q: A workflow (DAG) ran successfully but data was not loaded. Why?
First, open the workflow and check that the corresponding load exists in the workflow. If not, see I can't find a load from Workflow Orchestration. How to fix this? If the load exists, open the log of the load and check the output. Is a statement executed against a target database and has the statement produced rows.
-
If the target entity is a staging entity, has Agile Data Engine found source files to be loaded? (The log contains both No data files found to be loaded and No manifest files found to be loaded outputs). See Loading Source Data to understand how file loading works.
-
If the target entity is not a staging entity, do the source entities contain data or does the query contain a logical error?
-
If you are using Run ID Logic, has Agile Data Engine found loadable run ids? (Log output: Did not found any loadable run Id's for source and target.) See Using Run ID Logic to understand how run id loads work.
Q: A load is taking a long time. What should I do?
Open the logs of the load and check the output.
If the query has been sent to the target database, you will find INFO - Executing SQL output in the logs. If the query is not executed within 30 minutes, Workflow Orchestration checks if the connection is still active and outputs INFO - Database connection successful into the logs. This is repeated every 30 minutes and it means that for some reason the query execution is taking a long time. The right place to investigate more is the target database.
If you can't find a reason for the situation in the logs, start with Agile Data Engine's locks and after that with the target database's locks. Also see A deployment is taking a long time. What should I do? The situation is very similar even though Deployment Management executes DDL statements in the target database and Workflow Orchestration executes DML statements.
Q: I triggered a DAG but nothing happens. What can I do?
Check if the DAG is enabled.
Disabled DAG:
Enabled DAG:
If the DAG is enabled, check if the loads of the DAG waiting for slots to be released. Also see What are pools and slots in Workflow Orchestration?
Q: Can I cancel (mark failed/success) a load or a workflow in Workflow Orchestration?
This is not recommended as Agile Data Engine creates entity locks when it is processing entities, and mark failed/success does not release these locks. As a result, the entities can remain locked until locks are timed out which blocks deployments and loads into the entities. If your loads get stuck, cancel them from the target database instead. Use UTIL_CLEAN_ENTITY_LOCKS to release locks manually if necessary. Also see the notes in Workflow Orchestration.
Q: Why didn't my DAG execute on schedule?
Ensure that the DAG is visible and enabled in Workflow Orchestration (see I triggered a DAG but nothing happens. What can I do?), and that the cron expression is correctly defined (see CONFIG_LOAD_SCHEDULES). If all seems fine, check previous DAG executions in the past from the logs as Airflow sometimes lists them in a confusing order. It could be that the DAG was actually executed on schedule, but Airflow is listing earlier manual executions after the scheduled execution. This can happen due to Airflow's data interval concept which is explained in Airflow documentation.
Q: Why is the next run for a DAG in the past?
This is due to Airflow's data interval concept where a DAG is run after its associated data interval has ended. For example:
-
DAG is scheduled to run daily at 01:00
-
Airflow lists a run with id scheduled__2022-08-30T01:00:00+00:00
-
The run is actually executed at 2022-08-31, 01:00:00
See Airflow documentation for more information.