Guide objective
This guide explains how Run ID Logic works and presents examples of its common use cases.
Run ID Logic is a delta loading feature in Agile Data Engine that keeps track of data batches (run ids) that have been loaded between a source entity and a target entity. This enables selective loading of new data between the source-target pair, and loading it exactly once. Run ID Logic can be enabled in loads throughout the data warehouse zones to form a chain of incremental loads from e.g. staging to data warehouse to publish.
Run ID Logic also enables inserting change history data batch by batch in the correct order in cases where there are multiple source data batches queued. This is useful when loading change history tracking entities such as data vault satellites.
See also:
Understanding Run ID Logic
Run ids are running integer values that are written into a metadata attribute of technical type RUN_ID when loading data into a table (target run id), and used for filtering in outgoing loads when selecting data from the table (source run id). At least the source table in a run id load must have a run id attribute.
Default naming for run id attributes, for example:
-
stg_batch_id
-
stg_run_id
-
sdt_stage_batch_id
-
dv_run_id
The below diagram illustrates loading source data first into staging and then into further data warehouse tables using Run ID Logic (click image to enlarge):

File load and staging
When source data files are loaded into a staging table, source data batch ids are logged as loaded target run ids for that staging table. Batch id identifies a unique data batch extracted from a source. Incoming batch ids have to be notified using Notify API with the corresponding file addesses (see example in the above diagram). Batch ids can be notified on manifest level (multiple files per batch) or on manifest entry level (one file per batch).
Target run ids must be written into metadata columns (technical type RUN_ID) so that Agile Data Engine can filter queries when running loads from one table to another. Therefore, also source batch ids must be inserted into staging tables. Source batch ids can be written into the source file contents during data extraction by the integration process, or extracted from the file name during file load if the target database supports this. Notified batch ids must match the ids loaded into staging tables.
If you do not have control over source file generation and naming, it is possible to use the manifestrunid variable in an OVERRIDE_FILE_LOAD load step. With the variable, you can insert a manifest-level run id generated by Agile Data Engine into the staging table (again, if the target database supports this). Note that in this case you also do not need to notify batch ids as Agile Data Engine will generate them.
If you are using an external process to load source data into staging tables (i.e. you are not using file loads in Agile Data Engine), it is possible to post new run ids to be loaded using the External API (SaaS Enterprise and higher only). This way Agile Data Engine can take over loads onwards from staging while still using Run ID Logic. This can also be useful in some cases when running an initial load with a large amount of files. Rather than going through the Notify API process, files can be loaded into the staging table manually and their run ids added with an External API call.
See examples of different use cases below.
Further data warehouse loads
To enable Run ID Logic for a load:
-
Set OPT_USE_RUN_IDS = true
-
Optionally, define the number of run ids to be processed per transaction with OPT_NUM_RUN_IDS_PER_TRANSACTION
-
Optionally, set OPT_NUM_RUN_IDS_PER_TRANSACTION = -1 to start tracking run ids onwards from a load. This option allows you to start run id tracking from any load and you do not need to e.g. notify batch ids with Notify API or use External API to post new run ids. See example below.
Various Run ID Logic related variables can be utilized when using OVERRIDE load steps:
As presented in the diagram above, Agile Data Engine keeps track of which run ids have been loaded per source-target entity pair and this information is used in run id loads to filter the SELECT query from the source entity. This limits the amount of data to be processed to new records only. As run id logging is source-target specific, loads from a staging entity into several target entities can be executed in different schedules, and data can be persisted in staging if needed.
OPT_NUM_RUN_IDS_PER_TRANSACTION can be used to limit the number of run ids processed per transaction. In the above example, loads into dw.table_3 and dw.table_4 are loaded one run id at a time. This is useful when there can be multiple batches of source data queued to be loaded in one load execution, and change history needs to be stored in the correct order. Assuming that the source batch ids are in the correct order, data will end up into the target tables in the correct order as well.
Managing Run IDs with External API
Edition: SaaS Enterprise
Loaded run ids are stored in Agile Data Engine for about 30 days. Agile Data Engine will not load already loaded run ids again if such run ids are queued again during that period. On the other hand, Agile Data Engine will also not load run ids older than that period if a new run id load is introduced.
Run IDs can be searched, added and deleted using the Run ID Logic related functionalities in External API. There is a command line interface (CLI) tool available in Github to get started with External API. Also see the External API related examples below which utilize the CLI.
Notes
Run ID Logic currently only works with tables, not with e.g. views or materialized views.
External API is only available in SaaS Enterprise and higher editions, i.e. run IDs cannot be deleted in SaaS Standard edition. Create new batches to reload data in SaaS Standard or use the manifestrunid variable instead.
In the Private edition, run id API is found from the process-api service.
File loading practices and possibilities depend on the target database. Generally it is a good practice to generate batch ids in a data integration tool while extracting source data, write batch ids into source data files into a meta attribute, and notify batch ids to Agile Data Engine through Notify API when notifying new files.
Snowflake also enables extracting a batch id from a filename during a file load with metadata columns and transforming data during a load. This makes it optional to write the batch id into the source file content. See an example of this below.
The manifestrunid variable can be used in OVERRIDE_FILE_LOAD steps to insert a manifest-level run id into a staging table (if the target database supports this). Use this option to enable Run ID Logic even when you are not able to produce batch ids into source data files nor notify them. See how this would work in Azure SQL Database in the example below.
Run ID Logic is also supported in multi-source loads (loads with multiple entity mappings) so that one of the entity mappings is driving it. See entity mapping types for more information.
Examples
Snowflake: Extracting batch id from file name
Snowflake provides metadata columns for staged files which can be used to write file metadata into a staging table while running a COPY INTO statement. Follow this example to see how to extract the source data batch ids from file names in a file load.
Our example source files are in an S3 bucket which is defined in Snowflake as an external stage named staging.aws_stage. An external stage is required for transforming data during a load.
Source file foldering & naming convention:
{bucket}/{source_system}/{source_entity}/{yyyy}/{mm}/{dd}/{source_entity}.batch.{batch_id}.{file_type}.{compression}
Example files:
s3://demo-landing-bucket/barentswatch/ais_norway/2022/07/15/ais_norway.batch.1657875600000.json.gz
s3://demo-landing-bucket/barentswatch/ais_norway/2022/07/15/ais_norway.batch.1657879200000.json.gz
s3://demo-landing-bucket/barentswatch/ais_norway/2022/07/15/ais_norway.batch.1657882800000.json.gz
Note that in Snowflake stages are referenced with an @ character. The notification process must replace the actual S3 file path with an external stage reference and the relative file path. Also, the notified file specific batch ids have to match the ones in the file names.
Manifest entries posted to Notify API:
[
{
"batch": 1657875600000,
"sourceFile": "@staging.aws_stage/barentswatch/ais_norway/2022/07/14/ais_norway.batch.1657875600000.json.gz"
},
{
"batch": 1657879200000,
"sourceFile": "@staging.aws_stage/barentswatch/ais_norway/2022/07/14/ais_norway.batch.1657879200000.json.gz"
},
{
"batch": 1657882800000,
"sourceFile": "@staging.aws_stage/barentswatch/ais_norway/2022/07/14/ais_norway.batch.1657882800000.json.gz"
}
]
OVERRIDE_FILE_LOAD load step defined in the file load:
COPY INTO <target_schema>.<target_entity_name>
FROM (SELECT
regexp_substr(metadata$filename, 'batch\\.([0-9]*)\\.', 1, 1, 'e')::integer as stg_batch_id,
current_timestamp as stg_create_time,
'barentswatch' as stg_source_system,
'ais_norway' as stg_source_entity,
metadata$filename as stg_file_name,
$1 as payload
FROM
<from_path>
)
FILES = (<from_file_list>)
FILE_FORMAT = (<file_format>)
<copy_options>;
Here we are using the REGEXP_SUBSTR function to extract the batch id from the file name with a regular expression. At the same time we are also populating other metadata attributes in the staging table. The contents of the JSON files are written into a VARIANT column. Various Agile Data Engine variables are used to make the load dynamic; it supports manifests with one or multiple files, different file formats and load options.
Load SQL generated by Agile Data Engine:
COPY INTO staging.STG_BARENTSWATCH_AIS_JSON
FROM (SELECT
regexp_substr(metadata$filename, 'batch\\.([0-9]*)\\.', 1, 1, 'e')::integer as stg_batch_id,
current_timestamp as stg_create_time,
'barentswatch' as stg_source_system,
'ais_norway' as stg_source_entity,
metadata$filename as stg_file_name,
$1 as payload
FROM
'@staging.aws_stage/barentswatch/ais_norway/2022/07/15/'
)
FILES=(
'ais_norway.batch.1657875600000.json.gz',
'ais_norway.batch.1657879200000.json.gz',
'ais_norway.batch.1657882800000.json.gz')
FILE_FORMAT = (type='JSON' ...);
Azure SQL Database: Using manifestrunid with OVERRIDE_FILE_LOAD
Azure SQL Database allows transformations within a file load with the INSERT INTO ... SELECT ... FROM OPENROWSET pattern. Using this file load pattern, an Agile Data Engine generated manifest-level batch id can be inserted into a staging table with the manifestrunid variable.
With this file load pattern:
-
Metadata attributes including the source batch id do not need to be written into the source files before loading them into the target database.
-
Batch ids do not need to be notified.
-
Agile Data Engine generates a batch id on manifest level, i.e. files added to the same manifest must be of the same batch. Create single-file manifests if necessary.
When using OPENROWSET, a format file is usually required. See the provided Microsoft documentation links for more details.
Manifest entries posted to Notify API:
[{
"sourceFile": "digitraffic/locations_latest/2022/07/14/locations_latest_20220714001.csv"
}]
Note that the paths of manifest entries are relative to the external data source defined in the SQL database.
OVERRIDE_FILE_LOAD load step defined in the file load:
INSERT INTO <target_schema>.<target_entity_name>
SELECT
<manifestrunid> as stg_batch_id,
current_timestamp as stg_create_time,
'digitraffic' as stg_source_system,
'locations_latest' as stg_source_entity,
src.*
FROM OPENROWSET(
BULK <from_path>,
DATA_SOURCE = '<storage_integration>',
FORMATFILE = 'sql-format-files/<target_schema>.<target_entity_name>.xml',
FORMATFILE_DATA_SOURCE = '<storage_integration>',
FIRSTROW = 2
) src;
A run id will be automatically added using the manifestrunid variable, other metadata attributes can be defined as well. From_path is resolved as the notified file path and storage_integration as the external data source name during load execution. When using a format file, the format file location and data source must also be defined. Note that environment variables could be utilized here.
Load SQL generated by Agile Data Engine:
INSERT INTO staging.STG_DIGITRAFFIC_LOCATIONS_LATEST
SELECT
1657881333982 as stg_batch_id,
current_timestamp as stg_create_time,
'digitraffic' as stg_source_system,
'locations_latest' as stg_source_entity,
src.*
FROM OPENROWSET(
BULK 'digitraffic/locations_latest/2022/07/14/locations_latest_20220714001.csv',
DATA_SOURCE = 'dlsadedemo',
FORMATFILE = 'sql-format-files/staging.STG_DIGITRAFFIC_LOCATIONS_LATEST.xml',
FORMATFILE_DATA_SOURCE = 'dlsadedemo',
FIRSTROW = 2
) src;
Azure Synapse SQL: Using manifestrunid with OVERRIDE_FILE_LOAD
Azure Synapse SQL allows specifying a column list with default values within a COPY statement. This feature can be used as a workaround to insert an Agile Data Engine generated manifest-level batch id into a staging table with the manifestrunid variable.
With this file load pattern:
-
Metadata attributes including the source batch id do not need to be written into the source files before loading them into the target database. However, note that Azure Synapse SQL only supports constant default value definitions.
-
Batch ids do not need to be notified.
-
Agile Data Engine generates a batch id on manifest level, i.e. files added to the same manifest must be of the same batch. Create single-file manifests if necessary.
Manifest entries posted to Notify API:
[{
"sourceFile": "https://dlsadedemodev.blob.core.windows.net/raw/digitraffic/locations_latest/2022/07/14/locations_latest_20220714001.csv"
}]
OVERRIDE_FILE_LOAD load step defined in the file load:
COPY INTO <target_schema>.<target_entity_name>
(
stg_batch_id DEFAULT <manifestrunid> 101
,stg_source_system DEFAULT 'digitraffic' 102
,stg_source_entity DEFAULT 'locations_latest' 103
,mmsi 1
,type 2
,geometry 3
,geometry_coordinates 4
,properties_mmsi 5
,sog 6
,cog 7
,navstat 8
,rot 9
,posacc 10
,raim 11
,heading 12
,ts 13
,timestamp_external 14
)
FROM <from_path>
WITH (<file_format>);
Note how the target table attribute names are listed with their corresponding source file field indexes. Metadata attributes are specified with default values and dummy field indexes outside the source file field index range.
A run id will be automatically added using the manifestrunid variable, from_path is resolved as the notified file path (or list of paths), and file_format as the file format options during load execution.
Load SQL generated by Agile Data Engine:
COPY INTO staging.STG_DIGITRAFFIC_LOCATIONS_LATEST
(
stg_batch_id DEFAULT 1659440355273 101
,stg_source_system DEFAULT 'digitraffic' 102
,stg_source_entity DEFAULT 'locations_latest' 103
,mmsi 1
,type 2
,geometry 3
,geometry_coordinates 4
,properties_mmsi 5
,sog 6
,cog 7
,navstat 8
,rot 9
,posacc 10
,raim 11
,heading 12
,ts 13
,timestamp_external 14
)
FROM 'https://dlsadedemodev.blob.core.windows.net/raw/digitraffic/locations_latest/2022/07/14/locations_latest_20220714001.csv'
WITH (
FILE_TYPE = 'CSV',
CREDENTIAL=(IDENTITY= 'Managed Identity'),
FIELDQUOTE = '"',
FIELDTERMINATOR='|',
ENCODING = 'UTF8',
FIRSTROW = 2);
Using Run ID Logic together with Timeslot Logic
Combining Run ID Logic with Timeslot Logic can be very effective performance-wise especially in high-frequency incremental load use cases such as near real-time (NRT) workflows with large amounts of non-updating event or transaction data.
Data warehouse loads often have an existence check that avoids inserting duplicate entries into the target entity and this existence check often defines how heavy the load is. While Run ID Logic filters the incoming data from the source entity down to new records only, Timeslot Logic narrows down the existence check against the target entity when inserting those records:
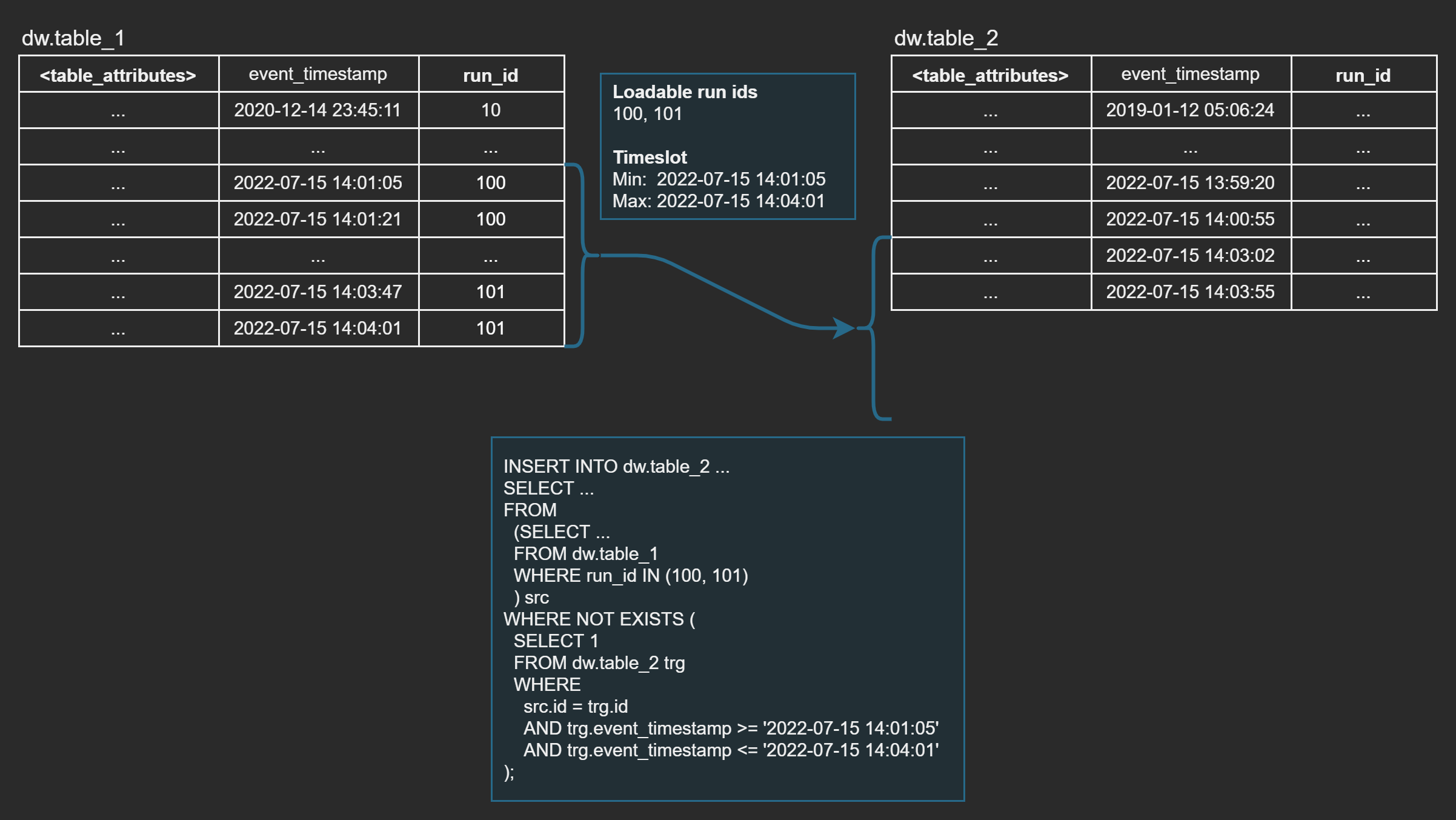
To enable timeslot logic:
-
Set OPT_USE_TIMESLOT_LOGIC to true
-
Set technical attribute type TIMESLOT for the timestamp attribute in the target entity
Smoke testing new records only
Run ID Logic can be used with smoke tests (SMOKE_GREY, SMOKE_BLACK) to limit testing to new records only. This is useful when testing entities with a lot of data and when there is no need to repeat the test for data that has already been tested before.
In this example, we will be testing an attribute for null or zero values so that only new records are tested:
|
Parameter |
Value |
|---|---|
|
Source entity |
STG_DIGITRAFFIC_METADATA_VESSELS |
|
Target entity |
H_MARINE_VESSEL_MMSI |
|
Tested attribute |
mmsi |
Run ID Logic enabled with: OPT_USE_RUN_IDS = true
SMOKE_GREY load step using the loadablerunids variable:
select count(1)
from staging_ms.STG_DIGITRAFFIC_METADATA_VESSELS
where
stg_run_id in (<loadablerunids>)
and (mmsi is null or mmsi = 0)
Smoke test executed by Agile Data Engine:
SELECT count(*) as cntresult
FROM (
select count(1)
from staging_ms.STG_DIGITRAFFIC_METADATA_VESSELS
where
stg_batch_id in (
1658110082143,
1658113682651,
1658117281752,
1658120881978,
1658124482459,
1658128082145)
and (mmsi is null or mmsi = 0)
) as cntquery
Loadablerunids is resolved as a list of run ids that have been queued between the source and target entities.
Note that Agile Data Engine adds a count query around the defined smoke test to ensure that data will not be transferred to the service.
Using Run ID Logic in a duplicate smoke test
Duplicate tests (SMOKE_GREY, SMOKE_BLACK) are often defined simply as grouping a table by the key attribute and checking if there are more than one rows per key:
SELECT 1
FROM <target_schema>.<target_entity_name>
GROUP BY id
HAVING COUNT(1) > 1;
This can work fine as long as the row count of the table is not too big.
With Run ID Logic, the duplicate test can be designed more efficiently as follows:
-- EXISTS operator will stop executing the subquery when the first entry is found from either of the UNION ALL legs
SELECT EXISTS (
-- Check first for duplicates within the latest batch that was loaded
SELECT 1
FROM <target_schema>.<target_entity_name> AS t0
WHERE t0.<targetrunidattr> = <targetrunid>
GROUP BY t0.id
HAVING COUNT(1) > 1
UNION ALL
-- Check for duplicates for the ids loaded in the latest batch vs. existing rows in the table
SELECT 1
FROM <target_schema>.<target_entity_name> AS t1
JOIN <target_schema>.<target_entity_name> AS t2 ON (t1.id = t2.id)
WHERE t1.<targetrunidattr> = <targetrunid> AND t2.<targetrunidattr> <> <targetrunid>
) AS duplicates_do_exist
-- If duplicates are found, then pass the info to the wrapping of the results i.e. cntquery
HAVING duplicates_do_exist = TRUE
Note that targetrunid must be inserted into the target entity in the same load.
This logic works well for incremental loads, reducing the amount of scanning the target database has to do to only the rows related to the latest loaded batch.
Deleting run ids with External API to reload data
Edition: SaaS Enterprise
This example uses the External API CLI tool and assumes that it has been installed and configured for the target environment.
In this example we will delete a previously loaded run id (source batch id) using External API to enable reloading data with the same source batch id.
|
Parameter |
Value |
|---|---|
|
Load id |
026c7f09-ce19-467c-9406-071547e1b91c |
|
Source entity |
staging.STG_DIGITRAFFIC_METADATA_VESSELS |
|
Source entity id |
451174ed-19b0-42f6-9316-07067fae1d91 |
|
Target entity |
rdv.H_MARINE_VESSEL_IMO |
|
Target entity id |
f5be588d-849c-4dc6-b074-fadca3301db5 |
|
Run id to be deleted |
1657951682127 |
First, we would like to list loaded run ids. Let's start by using the --help option to show available options:
ade run-ids search --help
Instructions will be printed:
Usage: ade run-ids search [OPTIONS]
Search run ids stored in target environment
Options:
--environment-name TEXT [required]
--load-id TEXT
--source-entity-id TEXT
--target-entity-id TEXT
--source-run-id INTEGER
--target-run-id INTEGER
--days INTEGER How many days backwards is searched for
--limit INTEGER Max amount of results returned
--help Show this message and exit.
Next, we will search for run ids using load-id and limit the search with days:
ade run-ids search --environment-name dev --load-id 026c7f09-ce19-467c-9406-071547e1b91c --days 1
Entity ids and load ids are visible in the Designer user interface. A load is developed as part of its target entity (see incoming loads for an entity), and its source entities are mapped in the entity mapping of the load.
The CLI tool lists run ids as a JSON array:
[
{
"runTimestamp": 1658021510257,
"targetRunId": 150,
"targetEntityId": "f5be588d-849c-4dc6-b074-fadca3301db5",
"loadId": "026c7f09-ce19-467c-9406-071547e1b91c",
"sourceRunId": 1657958881971,
"sourceEntityId": "451174ed-19b0-42f6-9316-07067fae1d91",
"affectedRows": 0
},
{
"runTimestamp": 1658021510257,
"targetRunId": 150,
"targetEntityId": "f5be588d-849c-4dc6-b074-fadca3301db5",
"loadId": "026c7f09-ce19-467c-9406-071547e1b91c",
"sourceRunId": 1657955282648,
"sourceEntityId": "451174ed-19b0-42f6-9316-07067fae1d91",
"affectedRows": 0
},
{
"runTimestamp": 1658021510257,
"targetRunId": 150,
"targetEntityId": "f5be588d-849c-4dc6-b074-fadca3301db5",
"loadId": "026c7f09-ce19-467c-9406-071547e1b91c",
"sourceRunId": 1657951682127,
"sourceEntityId": "451174ed-19b0-42f6-9316-07067fae1d91",
"affectedRows": 0
}
]
Where:
-
SourceRunId is the run id that Agile Data Engine used to filter the source entity when it ran the load into the target entity (loadablerunids).
-
TargetRunId is the run id that was written to the target entity (targetrunid) and what could be used again for further run id loads onwards from the target entity.
Now, let's see --help for the delete command:
ade run-ids delete --help
Instructions will be printed:
Usage: ade run-ids delete [OPTIONS]
Deletes run ids according to given search criteria.
Options:
--environment-name TEXT [required]
--load-id TEXT
--source-entity-id TEXT
--target-entity-id TEXT [required]
--source-run-id INTEGER
--target-run-id INTEGER
--from-run-timestamp INTEGER
--to-run-timestamp INTEGER
--help Show this message and exit.
Finally, let's run the delete command for the run id:
ade run-ids delete --environment-name dev --target-entity-id f5be588d-849c-4dc6-b074-fadca3301db5 --source-run-id 1657951682127
Success response:
OK
If we now trigger the load, the run id will be loaded again:
-- INFO - TargetRunId: 157, loaded runids: [1657951682127]
INSERT INTO rdv.H_MARINE_VESSEL_IMO
SELECT
...
157 AS dv_run_id
FROM staging.STG_DIGITRAFFIC_METADATA_VESSELS
WHERE
stg_batch_id IN (1657951682127)
...
Adding run ids with External API
Edition: SaaS Enterprise
This example uses the External API CLI tool and assumes that it has been installed and configured for the target environment.
In this example we will load source data to a database staging table manually and add a run id with External API to enable run id loads onwards from the staging table. This is useful e.g. for running an initial load; often there are lots of files and it is easier to load them manually with a folder path rather than notifying individual files.
|
Parameter |
Value |
|---|---|
|
Target entity |
staging.STG_DIGITRAFFIC_METADATA_VESSELS_JSON |
|
Target entity id |
e05e6bd4-4f4b-4d5b-b77b-26d55f85c83e |
|
Run id |
1658205691470 (current timemillis) |
We will start by loading source files from a given path to the staging table by running the COPY INTO statement manually in the database. We have given the current time in milliseconds since epoch as the run id for the batch. You could also specify e.g. file specific run ids. Note that the load is presented in Snowflake SQL but the process is similar in other databases.
COPY INTO staging.stg_digitraffic_metadata_vessels_json
FROM
(SELECT
1658205691470 as stg_batch_id,
current_timestamp as stg_create_time,
'digitraffic' as stg_source_system,
'metadata_vessels' as stg_source_entity,
metadata$filename as stg_file_name,
$1
FROM @AWS_STAGE/digitraffic/metadata_vessels/2022/07/19/)
FILE_FORMAT = (type='JSON' COMPRESSION = 'AUTO');
Next, we will add the run id with External API. Let's use the --help option first to show available options for the add command:
ade run-ids add --help
Note that you could also use the add-many command to add multiple run ids at the same time.
Instructions will be printed:
Usage: ade run-ids add [OPTIONS]
Add run ids to target env to be loaded.
Options:
--environment-name TEXT [required]
--affected-rows TEXT
--target-entity-id TEXT [required]
--target-run-id INTEGER [required]
--help Show this message and exit.
Run ids are added as target run ids for a target entity. In this case, our target entity is the staging table and our target run id is the given millisecond timestamp:
ade run-ids add --environment-name dev --target-entity-id e05e6bd4-4f4b-4d5b-b77b-26d55f85c83e --target-run-id 1658205691470
The response indicates success:
[
{
"runTimestamp": 1658206510876,
"targetRunId": 1658205691470,
"targetEntityId": "e05e6bd4-4f4b-4d5b-b77b-26d55f85c83e",
"loadId": null,
"sourceRunId": null,
"sourceEntityId": null,
"affectedRows": null
}
]
Finally, let's trigger the load and see the logs. Now we are interested in the outgoing loads from our staging entity where we added the run id. In this case there is one outgoing load to another staging table into which the loaded JSON files are parsed:
-- INFO - TargetRunId: 89, loaded runids: [1658205691470]
INSERT INTO staging.stg_digitraffic_metadata_vessels
SELECT
89 as stg_batch_id,
...
FROM staging.stg_digitraffic_metadata_vessels_json ...
WHERE stg_batch_id in (1658205691470);
Starting run id tracking from any load
Setting OPT_NUM_RUN_IDS_PER_TRANSACTION = -1 allows you to start tracking run ids onwards from any load. This is especially useful when data ingestion to staging is handled by a separate process and Notify API or External API is not used for posting new run ids.
In this example, a 3rd party process (separate from ADE) is ingesting data into the target database into TABLE_A which is represented in ADE by a METADATA_ONLY entity:

The load from METADATA_ONLY TABLE_A to ADE-managed table TABLE_B can be defined as follows:
-
Add an entity mapping specifying TABLE_A as source and TABLE_B as target entity, then map attributes and transformations as desired. Set RUN_ID as transformation type for the target run id attribute.
-
If you need to use OVERRIDE load steps instead of a generated load, remember to use the targetrunid variable to insert run ids into a run id attribute in TABLE_B.
-
Set load options:
-
OPT_USE_RUN_IDS = true
-
Load generated by ADE:
INSERT INTO TABLE_B (
...
)
SELECT DISTINCT
<targetrunid> AS run_id,
...
FROM
TABLE_A
At runtime, the selected rows from TABLE_A will be assigned a run id which will be inserted to TABLE_B. Run ID Logic can be used in the regular way in subsequent loads.
To add some delta logic into our example, let’s specify a PRE step that gets a max timestamp from TABLE_B into an SQL variable:
-- PRE step:
set max_timestamp = (select max(change_timestamp) from <target_schema>.<target_entity_name>);
Note that the syntax for using SQL variables varies between target database products.
Then use this variable with OPT_WHERE:
-- OPT_WHERE:
change_timestamp > coalesce($max_timestamp, '1900-01-01'::timestamp)
Load generated by ADE:
/* 1. set_max_timestamp (PRE - SQL) */
set max_timestamp = (select max(change_timestamp) from TABLE_B);
/* 2. (GENERATED - SQL) */
INSERT INTO TABLE_B (
...
)
SELECT DISTINCT
<targetrunid> AS run_id,
...
FROM
TABLE_A
WHERE
change_timestamp > coalesce($max_timestamp, '1900-01-01'::timestamp)
;
Note that additional load logic can be added with further use of load options.