Guide objective
This guide explains how you can customize a file load either by using load options or writing your own fully customized file load statement.
Load options can be used to customize the file load generated by Agile Data Engine when your file load does not contain transformations.
The OVERRIDE_FILE_LOAD load step type can be used when you need to fully customize a file load i.e. manually define the load SQL. With OVERRIDE_FILE_LOAD you can, for example, transform data during a file load, generate metadata attributes that are not part of the source file itself, or explicitly specify the copied data in a SELECT list.
Loading CSV Data
Example Data
The example CSV file used in this guide:
locationid, borough, zone, service_zone
1, EWR, Newark Airport, EWR
2, Queens, Jamaica Bay, Boro Zone
4, Manhattan, Alphabet City, Yellow Zone
Notification Process
The example source file is in an S3 bucket:
s3://example-data-bucket/tripdata-taxizone-csv/2023/08/29/taxi_zone_lookup.csv
The bucket is defined in Snowflake as an external stage named staging. An external stage is required for transforming data during a load. Note that in Snowflake stages are referenced with an @ character. The notification process must replace the actual S3 file path with an external stage reference and the relative file path:
"sourceFile": "@staging/tripdata-taxizone-csv/2023/08/29/taxi_zone_lookup.csv"
Agile Data Engine is notified (using Notify API) about the CSV file using the following data:
# Manifest request body:
{
"batch": 20230829010101,
"delim": "COMMA",
"format": "CSV",
"fullscanned": true,
"skiph": 1
}
# Manifest entry request body
{
"sourceFile": "@staging/tripdata-taxizone-csv/2023/08/29/taxi_zone_lookup.csv"
}
Loading Raw CSV
If the CSV file is loaded as is and you have only the four attributes in your staging entity, you don’t need to customize the file load.
The example table contains the following attributes:
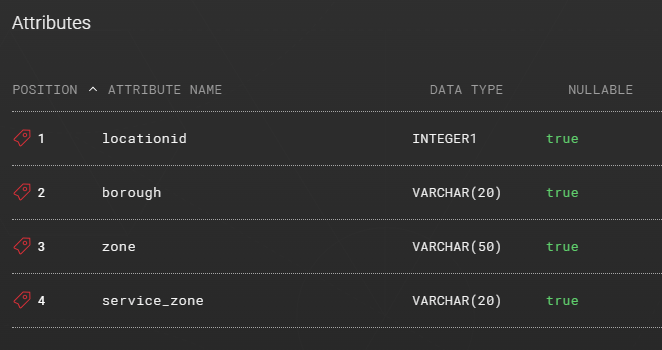
First create a load using LOAD_FILE load type and then map the source entity to the staging entity. If you notify Agile Data Engine about the new file using the above mentioned external stage (@stage), you don’t need to use the OPT_STORAGE_INTEGRATION load option.
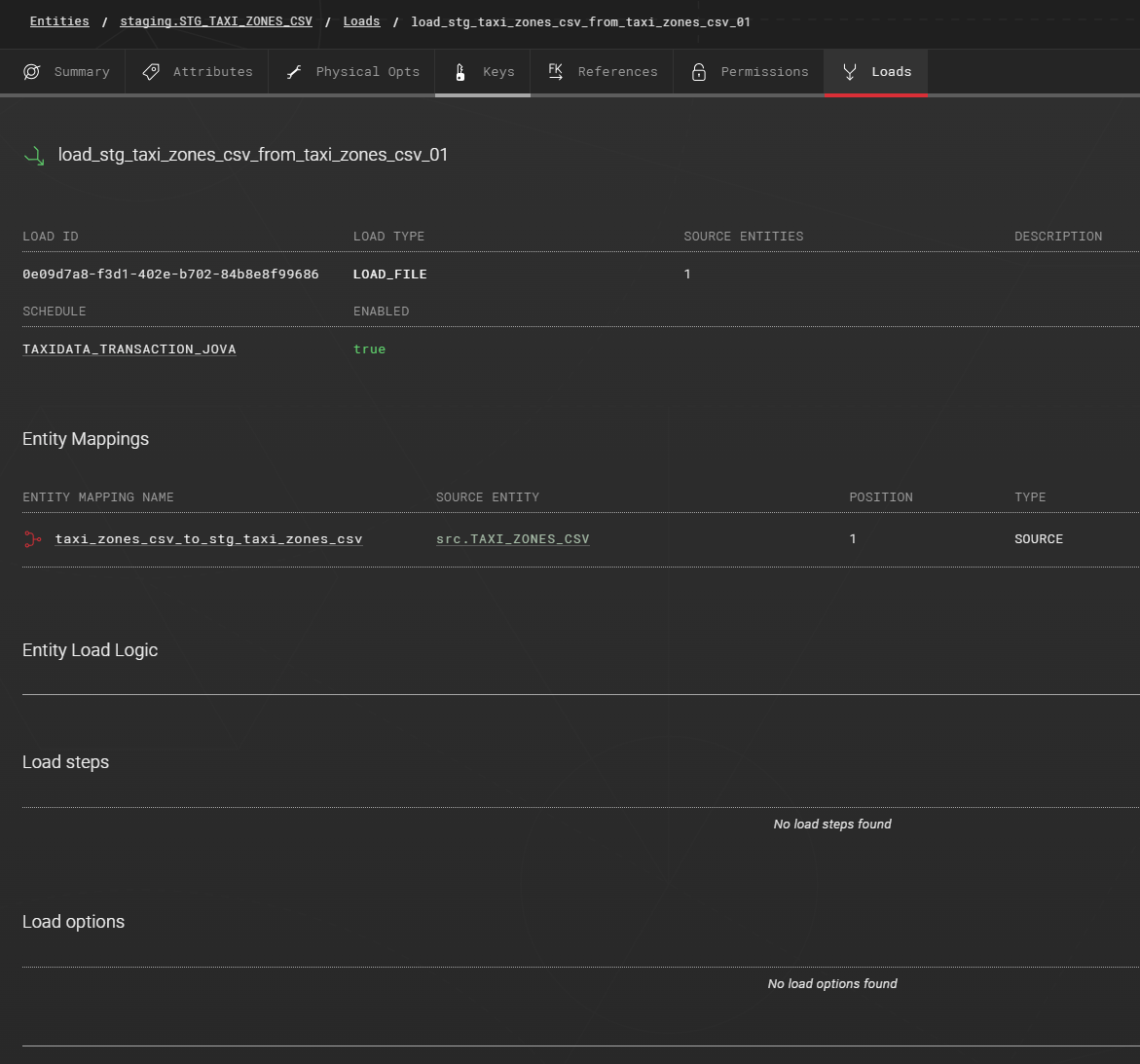
Agile Data Engine uses the following to form the load statement:
COPY INTO <target_schema>.<target_entity_name>
FROM <from_path>
FILE_FORMAT = (<file_format>)
FILES=(<from_file_list>)
The attributes are then replaced in Workflow Orchestration by the values given in Designer and in the notification:
COPY INTO staging.STG_TAXI_ZONES_CSV
FROM '@staging/tripdata-taxizone-csv/2023/08/29/'
FILE_FORMAT=(type='csv' skip_header=1 field_delimiter=',' FIELD_OPTIONALLY_ENCLOSED_BY='"' COMPRESSION='AUTO')
FILES=('taxi_zone_lookup.csv')
Transforming Data During CSV Load
If you have additional attributes in your staging table, you need to customize the file load using the OVERRIDE_FILE_LOAD load step type.
The example table contains the following attributes:
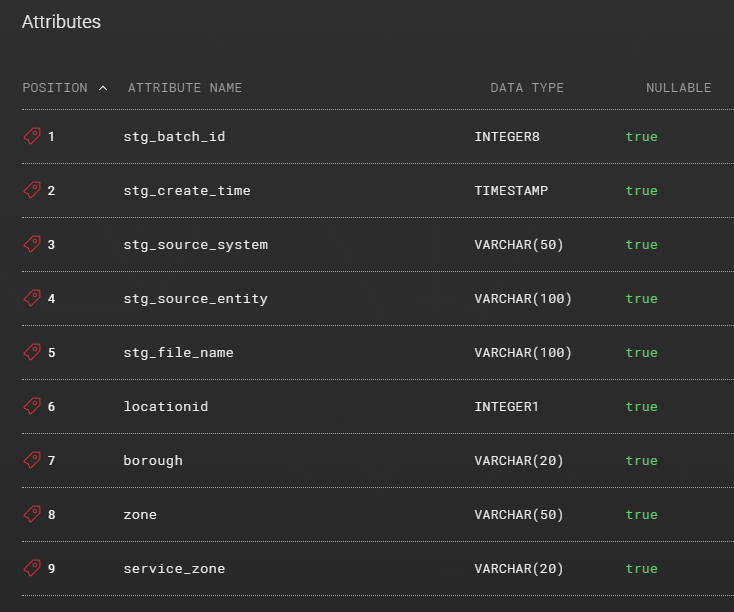
Create a LOAD_FILE load, map the source entity, and create an OVERRIDE_FILE_LOAD load step.
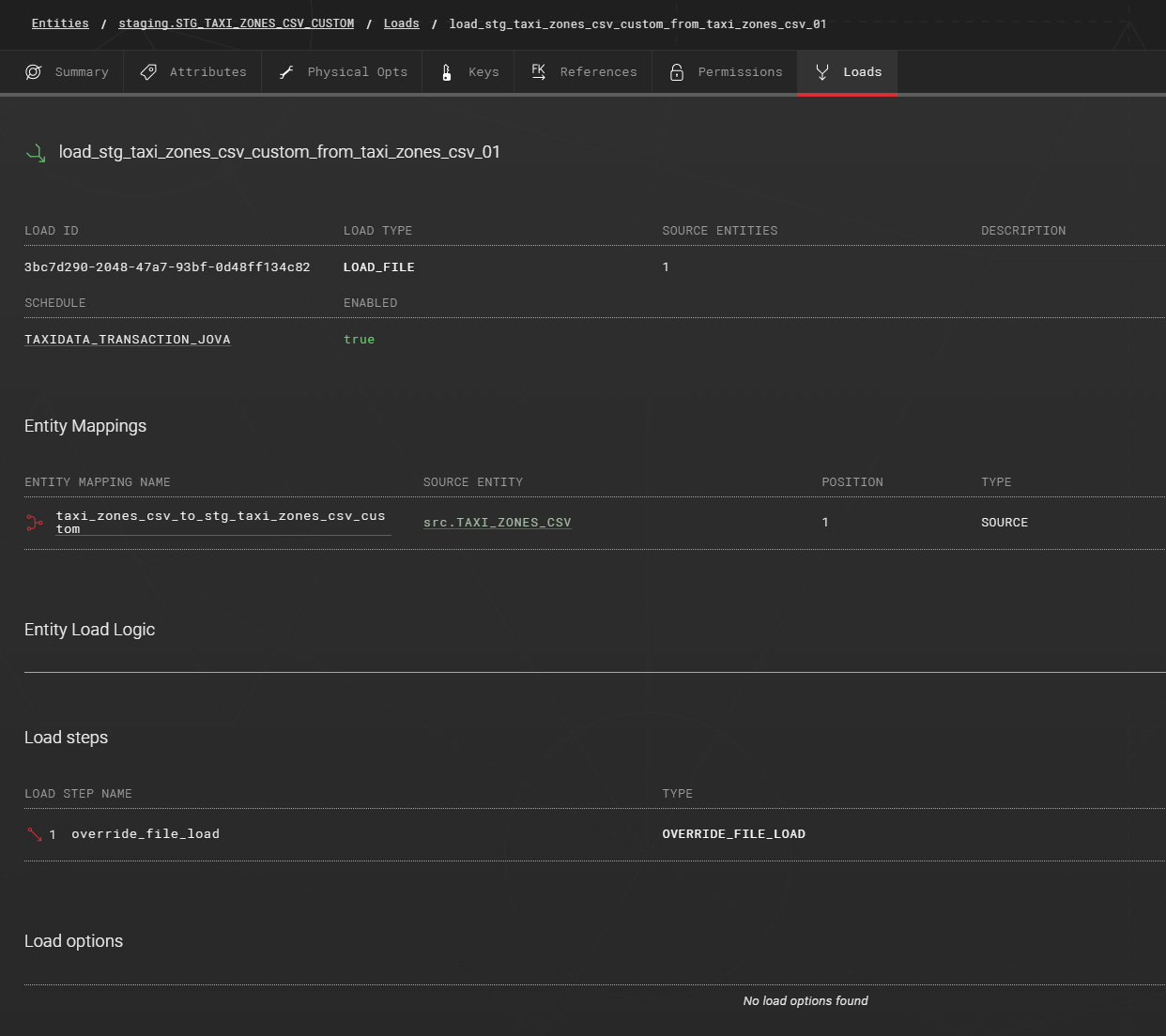
Add the following statement to the OVERRIDE_FILE_LOAD load step:
COPY INTO <target_schema>.<target_entity_name>
FROM (SELECT
<manifestrunid> as stg_batch_id,
current_timestamp as stg_create_time,
'taxidata' as stg_source_system,
'taxi_zone_lookup' as stg_source_entity,
metadata$filename as stg_file_name,
$1,
$2,
$3,
$4
FROM
<from_path>
)
FILES=(<from_file_list>)
FILE_FORMAT = (<file_format>);
The from_path, from_file_list, and manifestrunid variables are set based on the manifest content sent to Notify API. The file_format variable is set either based on the manifest content or on the OPT_FILE_FORMAT_OPTIONS load option. Metadata$filename is a Snowflake metadata column and it provides the path of the loaded file.
See also Snowflake’s guide on how to transform data during a load.
The attributes are then replaced in Workflow Orchestration by the values given in Designer and in the notification:
COPY INTO staging.STG_TAXI_ZONES_CSV
FROM (SELECT
20230829010101 as stg_batch_id,
current_timestamp as stg_create_time,
'taxidata' as stg_source_system,
'taxi_zone_lookup' as stg_source_entity,
metadata$filename as stg_file_name,
$1,
$2,
$3,
$4
FROM
'@staging/tripdata-taxizone-csv/2023/08/29/'
)
FILES=('taxi_zone_lookup.csv')
FILE_FORMAT = (type='csv' skip_header=1 field_delimiter=',' FIELD_OPTIONALLY_ENCLOSED_BY='"' COMPRESSION='AUTO')
Loading Parquet Data
Example Data
The representative example of the example Parquet file used in this guide:
[
{
"locationid": 1,
"borough": "EWR",
"zone": "Newark Airport",
"service_zone": "EWR"
},
{
"locationid": 2,
"borough": "Queens",
"zone": "Jamaica Bay",
"service_zone": "Boro Zone"
},
{
"locationid": 4,
"borough": "Manhattan",
"zone": "Alphabet City",
"service_zone": "Yellow Zone"
}
]
Notification Process
The example source file is in an S3 bucket:
s3://example-data-bucket/tripdata-taxizone-parquet/2023/08/29/taxi_zone_lookup.parquet
The bucket is defined in Snowflake as an external stage named staging. An external stage is required for transforming data during a load. Note that in Snowflake stages are referenced with an @ character. The notification process must replace the actual S3 file path with an external stage reference and the relative file path:
"sourceFile": "@staging/tripdata-taxizone-parquet/2023/08/29/taxi_zone_lookup.parquet"
Agile Data Engine is notified (using Notify API) about the PARQUET file using the following values:
# Manifest request body:
{
"batch": 20230829010101,
"format": "UNKNOWN"
}
# Manifest entry request body
{
"sourceFile": "@staging/tripdata-taxizone-parquet/2023/08/29/taxi_zone_lookup.parquet"
}
Loading Raw Parquet
If the Parquet file is loaded as is and you have only the four attributes in your staging entity, you don’t need to write your own file load.
The example table contains the following attributes:
First create a load using the LOAD_FILE load type, then map the source entity to the staging entity, and finally add OPT_FILE_FORMAT_OPTIONS and OPT_SF_FILE_COPY_OPTIONS load options with values provided later.
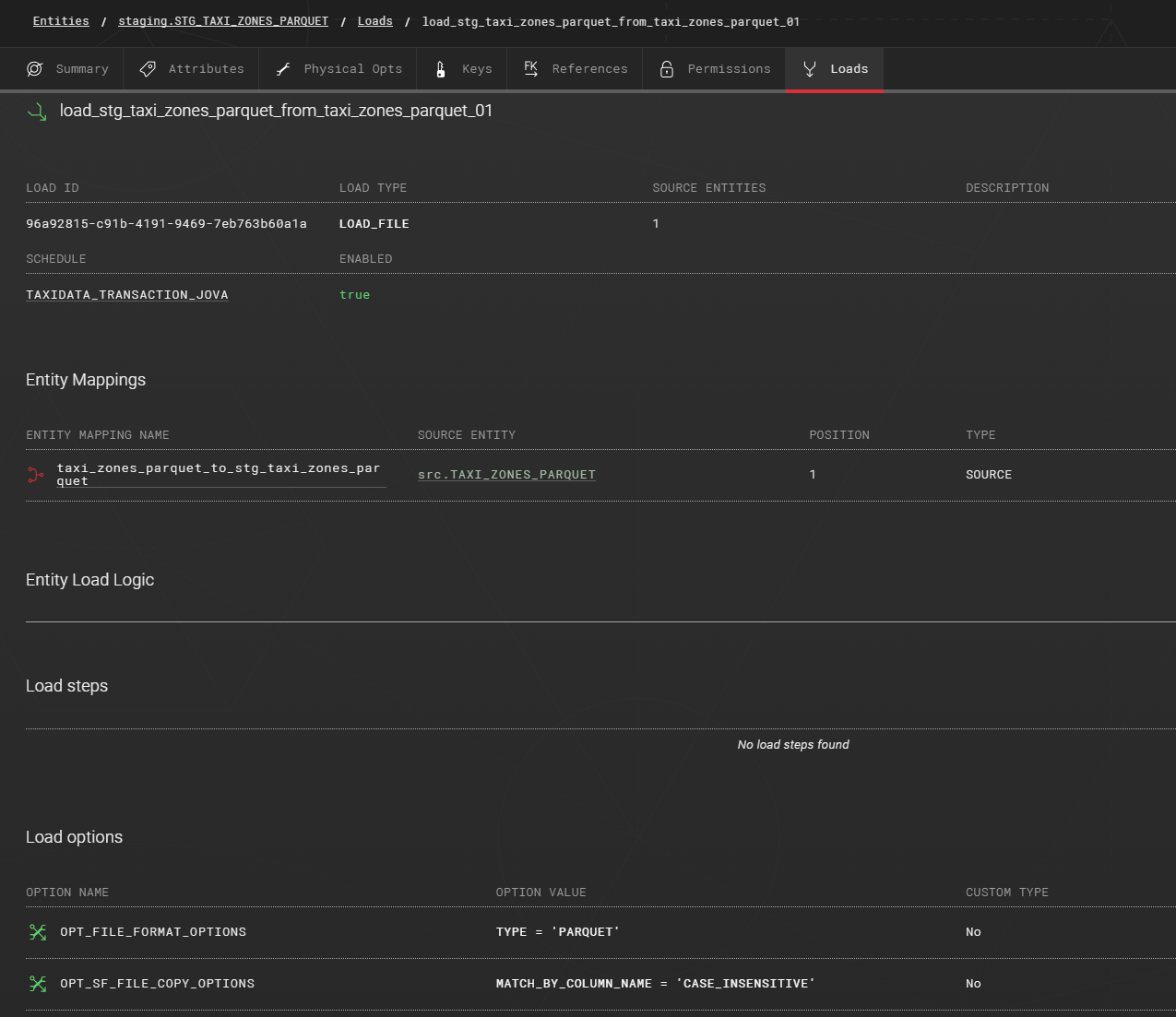
Set the following values to the corresponding load options:
OPT_FILE_FORMAT_OPTIONS:
TYPE = 'PARQUET'
USE_VECTORIZED_SCANNER = TRUE
OPT_SF_FILE_COPY_OPTIONS: MATCH_BY_COLUMN_NAME = 'CASE_INSENSITIVE'
The USE_VECTORIZED_SCANNER file format option can improve performance when reading Parquet. See Snowflake documentation for detailed information.
Agile Data Engine uses the following to form the load statement:
COPY INTO <target_schema>.<target_entity_name>
FROM <from_path>
FILE_FORMAT = (<file_format>)
FILES=(<from_file_list>)
The attributes are then replaced in Workflow Orchestration by the values given in Designer and in the notification:
COPY INTO staging.STG_TAXI_ZONES_PARQUET
FROM '@staging/tripdata-taxizone-parquet/2023/08/29/'
FILE_FORMAT=(TYPE = 'PARQUET' USE_VECTORIZED_SCANNER = TRUE)
FILES=('taxi_zone_lookup.parquet')
MATCH_BY_COLUMN_NAME = 'CASE_INSENSITIVE'
Transforming Data During Parquet Load
If you have additional attributes in your staging table, you need to customize the file load using OVERRIDE_FILE_LOAD load step type.
The example table contains the following attributes:
First create a load using the LOAD_FILE load type, then map the source entity to the staging entity, and finally add the OPT_FILE_FORMAT_OPTIONS load option with a value provided later.
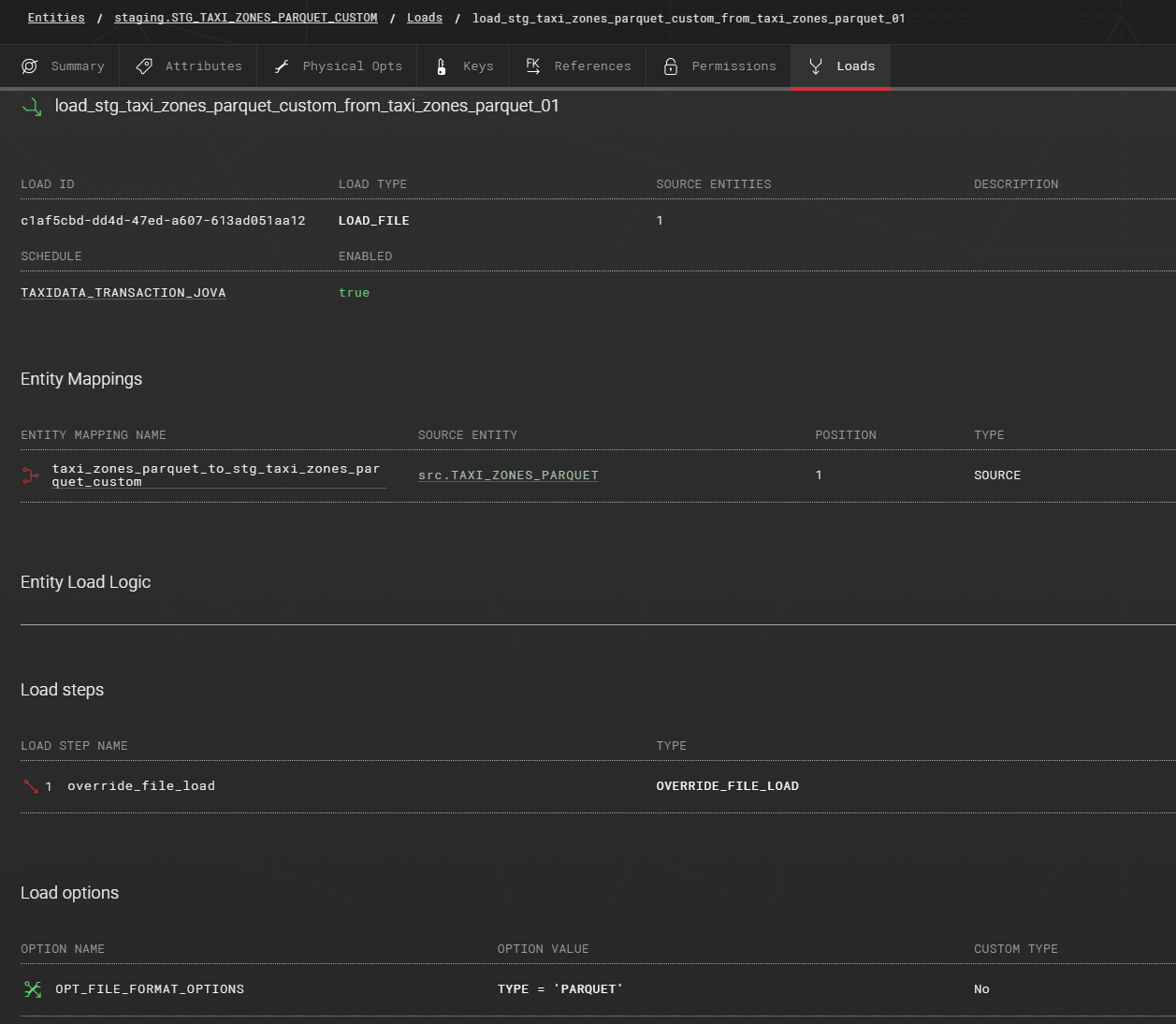
Set the following value to the load option:
OPT_FILE_FORMAT_OPTIONS:
TYPE = 'PARQUET'
USE_VECTORIZED_SCANNER = TRUE
The USE_VECTORIZED_SCANNER file format option can improve performance when reading Parquet. See Snowflake documentation for detailed information.
Add the following statement to the OVERRIDE_FILE_LOAD load step:
COPY INTO <target_schema>.<target_entity_name>
FROM (SELECT
<manifestrunid> as stg_batch_id,
current_timestamp as stg_create_time,
'<source_system_name>' as stg_source_system,
'<source_entity_name>' as stg_source_entity,
metadata$filename as stg_file_name,
$1:locationid::integer,
$1:borough::varchar,
$1:zone::varchar,
$1:service_zone::varchar
FROM
<from_path>
)
FILES=(<from_file_list>)
FILE_FORMAT = (<file_format>);
The from_path, from_file_list, and manifestrunid variables are set based on the manifest content sent to Notify API. The file_format variable is set either based on the manifest content or on the OPT_FILE_FORMAT_OPTIONS load option. Metadata$filename is a Snowflake metadata column and it provides the path of the loaded file. The source_system_name and source_entity_name variables can be used for additional metadata.
See also Snowflake’s guide on how to transform data during a load.
Generated load:
COPY INTO staging.STG_TAXI_ZONES_PARQUET
FROM (SELECT
20230829010101 as stg_batch_id,
current_timestamp as stg_create_time,
'taxidata' as stg_source_system,
'taxi_zone_lookup' as stg_source_entity,
metadata$filename as stg_file_name,
$1:locationid::integer,
$1:borough::varchar,
$1:zone::varchar,
$1:service_zone::varchar
FROM
'@staging/tripdata-taxizone-parquet/2023/08/29/'
)
FILES=('taxi_zone_lookup.parquet')
FILE_FORMAT=(TYPE = 'PARQUET' USE_VECTORIZED_SCANNER = TRUE)
Alternatively, you can define the transformations in the attribute mapping instead and use variable target_entity_attribute_list_with_transform_cast_parquet in the OVERRIDE_FILE_LOAD load step.
You can use variables in the attribute mapping with the CUSTOM transformation type for the metadata attributes and then add 1:1 mappings for all the source attributes to target:
|
Source attribute |
Target attribute |
Transformation |
|---|---|---|
|
- |
stg_batch_id |
CUSTOM: |
|
- |
stg_create_time |
CURRENT_TS |
|
- |
stg_source_system |
CUSTOM: |
|
- |
stg_source_entity |
CUSTOM: |
|
- |
stg_file_name |
CUSTOM: |
|
locationid |
locationid |
NONE |
|
borough |
borough |
NONE |
|
… |
… |
… |
Then define the OVERRIDE_FILE_LOAD load step:
COPY INTO <target_schema>.<target_entity_name>
FROM (SELECT
<target_entity_attribute_list_with_transform_cast_parquet>
FROM
<from_path>
)
FILES=(<from_file_list>)
FILE_FORMAT = (<file_format>);
Note that if the load pattern is repeated in many places, it’s a good practice to define new transformation types for populating metadata attributes in CONFIG_LOAD_TRANSFORMATIONS instead of using the CUSTOM transformation type. You can also set transformation types as default for the metadata attributes in CONFIG_ENTITY_DEFAULTS.
Also the load steps and load options can be saved as a template and set as default for the entity type.
Generated load:
COPY INTO staging.STG_TAXI_ZONES_PARQUET
FROM (SELECT
20230829010101 as stg_batch_id
, CURRENT_TIMESTAMP::timestamp_ntz as stg_create_time
, 'taxidata' as stg_source_system
, 'taxi_zone_lookup' as stg_source_entity
, metadata$filename as stg_file_name
, GET_IGNORE_CASE($1,'locationid')::INTEGER AS locationid
, GET_IGNORE_CASE($1,'borough')::TEXT AS borough
, GET_IGNORE_CASE($1,'zone')::TEXT AS zone
, GET_IGNORE_CASE($1,'service_zone')::TEXT AS service_zone
FROM
'@staging/tripdata-taxizone-parquet/2023/08/29/'
)
FILES=('taxi_zone_lookup.parquet')
FILE_FORMAT=(TYPE = 'PARQUET' USE_VECTORIZED_SCANNER = TRUE)
Loading Parquet from an External Table
This example is different from the other examples in this article as here:
-
Load type TRANSFORM_PERSIST is used instead of LOAD_FILE
-
Source file notifications are not needed
-
Data is loaded from an external table with an INSERT INTO … SELECT statement instead of COPY INTO
-
The external table is represented in ADE by a METADATA_ONLY entity with an external table creation statement as a load step
Source data is stored in cloud object storage as Parquet files partitioned as follows:
path_to_files/yyyy/mm/dd/file_name.parquet
The following entities are created:
|
Name |
Entity type |
Physical type |
Description |
|---|---|---|---|
|
src.AIS_POSITION |
SOURCE |
METADATA_ONLY |
SOURCE entity representing the source data with its attributes and data types. |
|
staging.EXT_AIS_POSITION |
SOURCE |
METADATA_ONLY |
Representing the external table. External table object defined in a load step (see below). |
|
staging.STG_AIS_POSITION |
STAGE |
TABLE |
Staging table where the data will be loaded from the external table. |
External table
The external table is defined in a load with an entity mapping from src.AIS_POSITION to staging.EXT_AIS_POSITION:
|
Source attribute |
Target attribute |
Transformation |
|---|---|---|
|
- |
date_part |
CUSTOM: SQL
|
|
- |
stg_file_name |
FILE_PATH_EXTERNAL |
|
type |
type |
NONE |
|
mmsi |
mmsi |
NONE |
|
… |
… |
… |
Where:
-
Date_part will be used as a partition column for the external table. The folder path is used for constructing the date. Read more about external tables and partitioning in Snowflake documentation.
-
FILE_PATH_EXTERNAL is a transformation type defined in CONFIG_LOAD_TRANSFORMATIONS which for Snowflake is resolved as metadata$filename.
-
Source entity attributes are mapped 1:1 to target without transformations.
An OVERRIDE load step is defined as follows:
create or replace external table <target_schema>.<target_entity_name> (
<target_entity_attribute_list_with_transform_cast_exttable_parquet>
)
partition by (date_part)
location = @stage_name/path_to_files/
file_format = (type = parquet)
refresh_on_create = true
auto_refresh = false;
Where:
-
Variable target_entity_attribute_list_with_transform_cast_exttable_parquet will list the mapped transformations and variables when the load is generated
-
The constructed DATE column date_part is used as a partition column
-
An external stage & relative folder path is referenced
-
External table is set to refresh on create
Generated load:
create or replace external table staging.EXT_AIS_POSITION (
date_part DATE AS TO_DATE(
SPLIT_PART(metadata$filename, '/', 3) || '/' ||
SPLIT_PART(metadata$filename, '/', 4) || '/' ||
SPLIT_PART(metadata$filename, '/', 5)
,'YYYY/MM/DD'
)
, stg_file_name TEXT AS metadata$filename
, type TEXT AS TO_VARCHAR(GET_IGNORE_CASE($1, 'type'))
, mmsi NUMBER(38,0) AS TO_DECIMAL(GET_IGNORE_CASE($1, 'mmsi'),38,0)
, msgtime TIMESTAMP AS TO_TIMESTAMP_NTZ(GET_IGNORE_CASE($1, 'msgtime'))
, messagetype NUMBER(38,0) AS TO_DECIMAL(GET_IGNORE_CASE($1, 'messagetype'),38,0)
, altitude NUMBER(38,0) AS TO_DECIMAL(GET_IGNORE_CASE($1, 'altitude'),38,0)
, courseoverground NUMBER(20,10) AS TO_DECIMAL(GET_IGNORE_CASE($1, 'courseoverground'),20,10)
, latitude NUMBER(20,10) AS TO_DECIMAL(GET_IGNORE_CASE($1, 'latitude'),20,10)
, longitude NUMBER(20,10) AS TO_DECIMAL(GET_IGNORE_CASE($1, 'longitude'),20,10)
, navigationalstatus NUMBER(38,0) AS TO_DECIMAL(GET_IGNORE_CASE($1, 'navigationalstatus'),38,0)
, aisclass TEXT AS TO_VARCHAR(GET_IGNORE_CASE($1, 'aisclass'))
, rateofturn NUMBER(20,10) AS TO_DECIMAL(GET_IGNORE_CASE($1, 'rateofturn'),20,10)
, speedoverground NUMBER(20,10) AS TO_DECIMAL(GET_IGNORE_CASE($1, 'speedoverground'),20,10)
, trueheading NUMBER(38,0) AS TO_DECIMAL(GET_IGNORE_CASE($1, 'trueheading'),38,0)
)
partition by (date_part)
location = @stage_name/path_to_files/
file_format = (type = parquet)
refresh_on_create = true
auto_refresh = false;
Load to staging table
A load to the staging table from the METADATA_ONLY entity representing the external table is defined as follows.
There is an entity mapping:
|
Source attribute |
Target attribute |
Transformation |
|---|---|---|
|
- |
stg_batch_id |
RUN_ID |
|
- |
stg_create_time |
CURRENT_TS |
|
- |
stg_source_system |
SOURCE_SYSTEM_NAME |
|
- |
stg_source_entity |
SOURCE_ENTITY_NAME |
|
stg_file_name |
stg_file_name |
NONE |
|
type |
type |
NONE |
|
mmsi |
mmsi |
NONE |
|
… |
… |
… |
Where:
-
SOURCE_SYSTEM_NAME and SOURCE_ENTITY_NAME are transformation types configured in CONFIG_LOAD_TRANSFORMATIONS, resolved as the source_system_name and source_entity_name variables.
-
Stg_file_name was defined in the external table so it can be directly mapped to target.
-
Other source attributes are directly mapped to target without transformations.
In a PRE step we get the current maximum timestamp from the staging table into an SQL variable which will be used to filter the query on the external table:
set max_date = (select max(msgtime)::date from <target_schema>.<target_entity_name>);
Additionally, the following load options are defined:
|
Option name |
Option value |
Description |
|---|---|---|
|
true |
Disables DISTINCT in the generated load. |
|
|
SQL
|
Uses the SQL variable defined in the PRE step to filter data from the external table. ‘1900-01-01’ is used if null. |
|
|
true |
Enables Run ID logic. |
|
|
-1 |
Enables starting run id tracking “from scratch”, see details in this example. |
Note that no OVERRIDE step is needed in this example.
Generated load:
/* 1. get_max_timestamp (PRE - SQL) */
set max_date = (select max(msgtime)::date from staging.STG_AIS_POSITION);
/* 2. (GENERATED - SQL) */
INSERT INTO staging.STG_AIS_POSITION (
stg_batch_id
, stg_create_time
, stg_source_system
, stg_source_entity
, stg_file_name
, type
, mmsi
, msgtime
, messagetype
, altitude
, courseoverground
, latitude
, longitude
, navigationalstatus
, aisclass
, rateofturn
, speedoverground
, trueheading
)
SELECT
<targetrunid> AS stg_batch_id
, CURRENT_TIMESTAMP::timestamp_ntz AS stg_create_time
, 'MARINE_DATA' AS stg_source_system
, 'EXT_AIS_POSITION' AS stg_source_entity
, stg_file_name AS stg_file_name
, type AS type
, mmsi AS mmsi
, msgtime AS msgtime
, messagetype AS messagetype
, altitude AS altitude
, courseoverground AS courseoverground
, latitude AS latitude
, longitude AS longitude
, navigationalstatus AS navigationalstatus
, aisclass AS aisclass
, rateofturn AS rateofturn
, speedoverground AS speedoverground
, trueheading AS trueheading
FROM
staging.EXT_AIS_POSITION src_entity
WHERE
date_part >= coalesce($max_date, '1900-01-01'::date)
;