Agile Data Engine supports multiple architectural approaches for ingesting data into the target database. The most suitable approach depends on your organization’s tools, preferences, and integration patterns.
Importantly, these approaches are not mutually exclusive, you can combine them as needed to meet the specific requirements of different use cases across your data platform.
Option 1A: Ingesting Data from Cloud Storage with ADE and Notify API
Agile Data Engine can orchestrate data ingestion from cloud storage (e.g. Amazon S3, Azure Blob Storage, Google Cloud Storage) into the target database by executing file load operations. These operations are implemented using platform-specific commands such as COPY INTO, LOAD DATA, or BULK INSERT, depending on the target database.
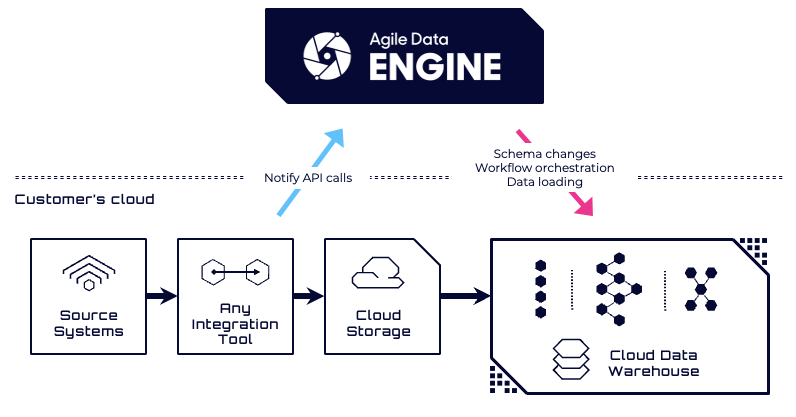
In this pattern, the Notify API must be called by an external process to inform ADE that new source data files are available. When a file is posted to the Notify API, it is queued, waiting for its corresponding load to be executed. ADE will then use the provided file paths in the load statement it orchestrates, enabling automated and controlled ingestion of incoming data.
To enable this pattern, some prerequisites must be in place:
-
ADE File Notifier must be set up in the your cloud environment. This application detects file events and posts file paths to the Notify API.
-
Cloud-specific infrastructure (e.g., storage event triggers or messaging services) is required to support this setup.
See Getting started with Notify API and Loading Source Data for further instructions.
Benefits of using Notify API:
This approach is typically the recommended option for data ingestion. While it requires some initial setup, it offers the most control over the ingestion process:
-
ADE orchestrates the entire pipeline from cloud storage to the data warehouse.
-
It allows precise control over which files are loaded per file load statement, which is especially useful for reload scenarios and performance optimization.
-
Data ingestion and transformation logs are in the same tool.
Option 1B: Ingesting Data from Cloud Storage with ADE (without Notify API)
This pattern is similar to Option 1A, but it does not rely on the Notify API. Agile Data Engine still orchestrates file load statements in the target database, but instead of referencing specific file paths, the statements use folder-level paths.
In this case, the target database handles the detection of new files within the specified location and loads only the ones that haven’t been processed. This simplifies orchestration logic but relies on the capabilities of the target system.
In practice, this pattern can be followed by implementing the load as type TRANSFORM_PERSIST instead of LOAD_FILE and adding the load statement (e.g. COPY INTO) as an OVERRIDE load step.
Note that his approach is supported only by certain databases that natively manage file tracking and deduplication, such as Databricks SQL and Snowflake.
Benefits of this approach include:
-
Minimal setup required, ideal for proof-of-concept (PoC) or early-stage development.
-
ADE still orchestrates the file loads, so logging and monitoring remain centralized.
Trade-offs:
-
Less control over which files are loaded; relies on the target system’s internal tracking.
-
Reload scenarios can be more complex.
-
Loading from paths with a large number of files may impact performance.
Option 2: Using an External Data Ingestion Tool
In this pattern, a dedicated data ingestion solution is used to load data into the target database. This could be a third-party ETL/ELT tool or a database-native ingestion feature such as Databricks Streaming Tables or Snowflake Snowpipe.
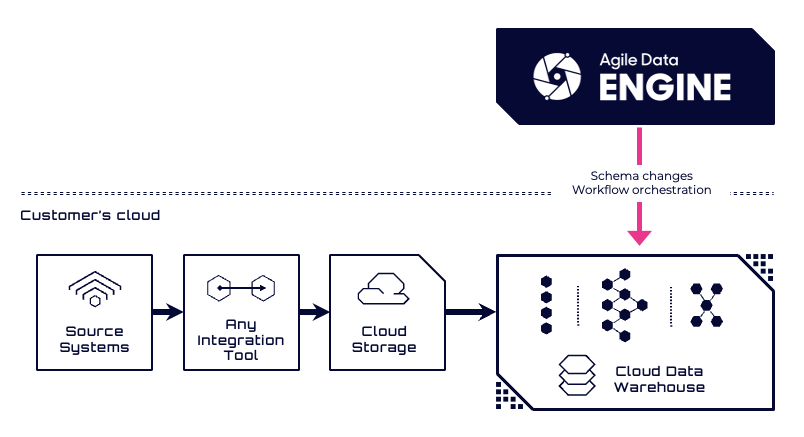
In this model, ADE focuses on downstream transformations, metadata management, and orchestration on top of the ingested data.
This approach is suitable when ingestion processes are already established or when leveraging real-time and continuous ingestion tools provided by the target platform.
See Data Ingestion with External Tools for further details. For examples with database-native ingestion features, see:
-
Snowflake Snowpipe creation (dynamic tables solution example)
Benefits of this approach include:
-
You have the freedom to choose any ingestion tool that fits your architecture.
-
The ingestion process can be tightly integrated with the data extraction process.
-
Some ETL/ELT tools can automatically adapt staging schemas when source data structures change.
-
Database-native ingestion features may offer near real-time capabilities.
Trade-offs:
-
You must monitor and orchestrate ingestion separately from ADE.
-
There is no built-in synchronization between ingestion and ADE-managed transformations or deployments, which can complicate pipeline coordination.