Data ingestion into the target database can be performed using any suitable external tool. In such cases, ADE can continue the process from already ingested data, taking over from there to manage data development, transformations, and orchestration.
When ADE is not responsible for the ingestion process, the following considerations apply:
-
Monitoring: The ingestion process must be monitored using the external tool to ensure data arrives as expected. ADE smoke tests can also be used to test for data freshness.
-
Schema management: If the landing tables are not created by ADE, also the schema must be maintained by external tools, including handling any changes.
-
Metadata management in ADE: Metadata for the landing tables must be maintained and kept up to date in ADE so that transformations and downstream logic can be built on top of them.
Adding existing tables to ADE
When raw data has already been ingested into the target database, you will need to import entity metadata into Agile Data Engine to represent it. To do this, refer to the Importing Initial Metadata guide.
Metadata definition of existing data
In this example, the target database already contains a table named raw.SRC_ORDERS. The metadata definition for this table has been imported into Agile Data Engine using the entity import feature.
The entity is defined with:
-
Entity type:
SOURCE -
Physical type:
METADATA_ONLY
This setup means the entity in ADE represents only the metadata of the existing table and is not managed or deployed by ADE.
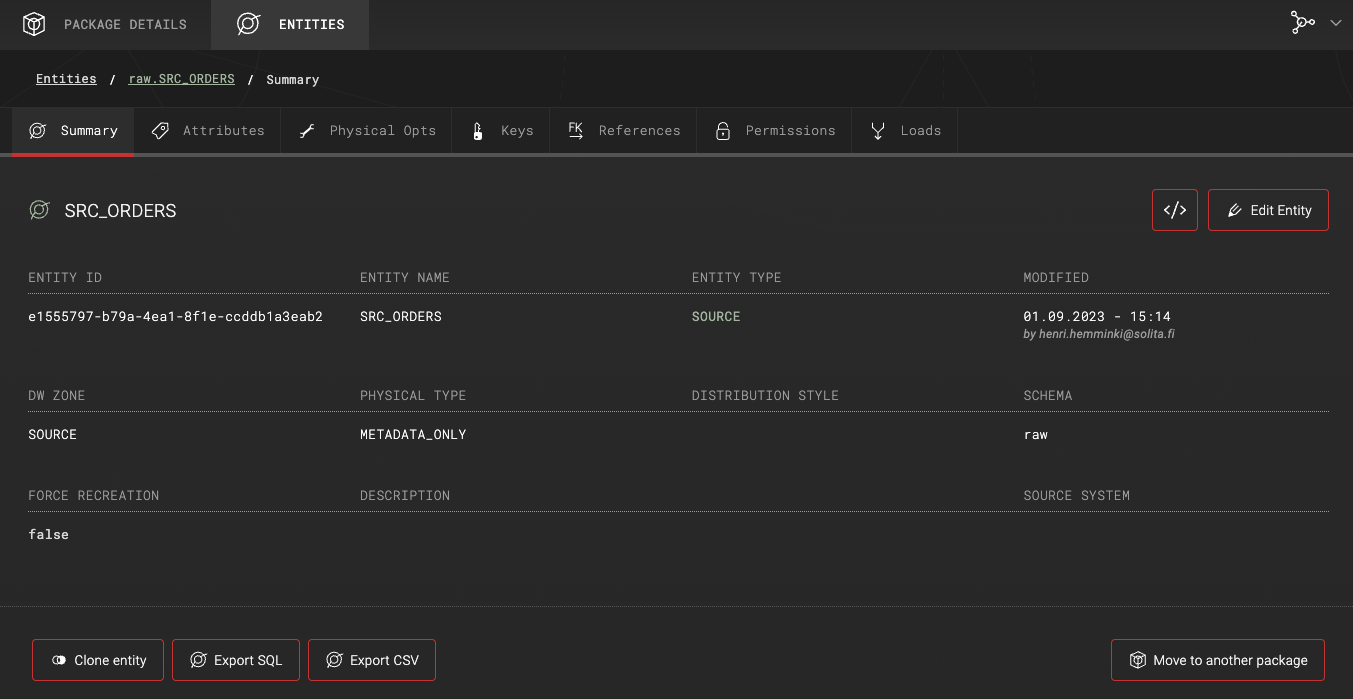
Table attributes:
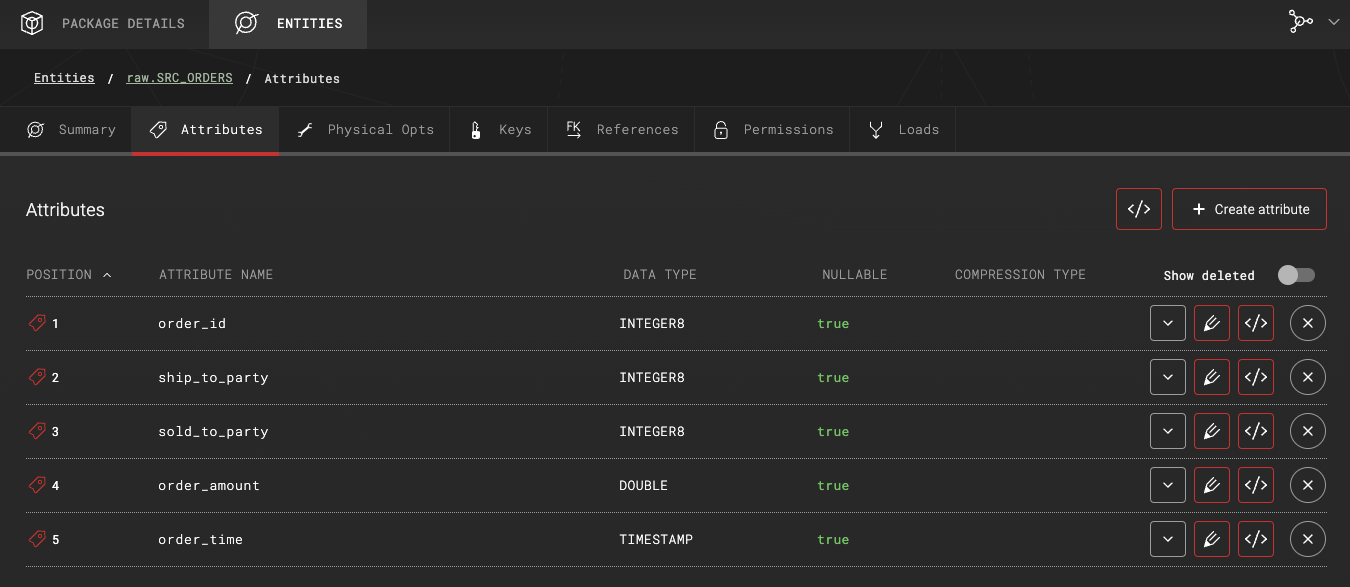
When the metadata definition exists in ADE, it is possible to map this entity in downstream entities and loads.
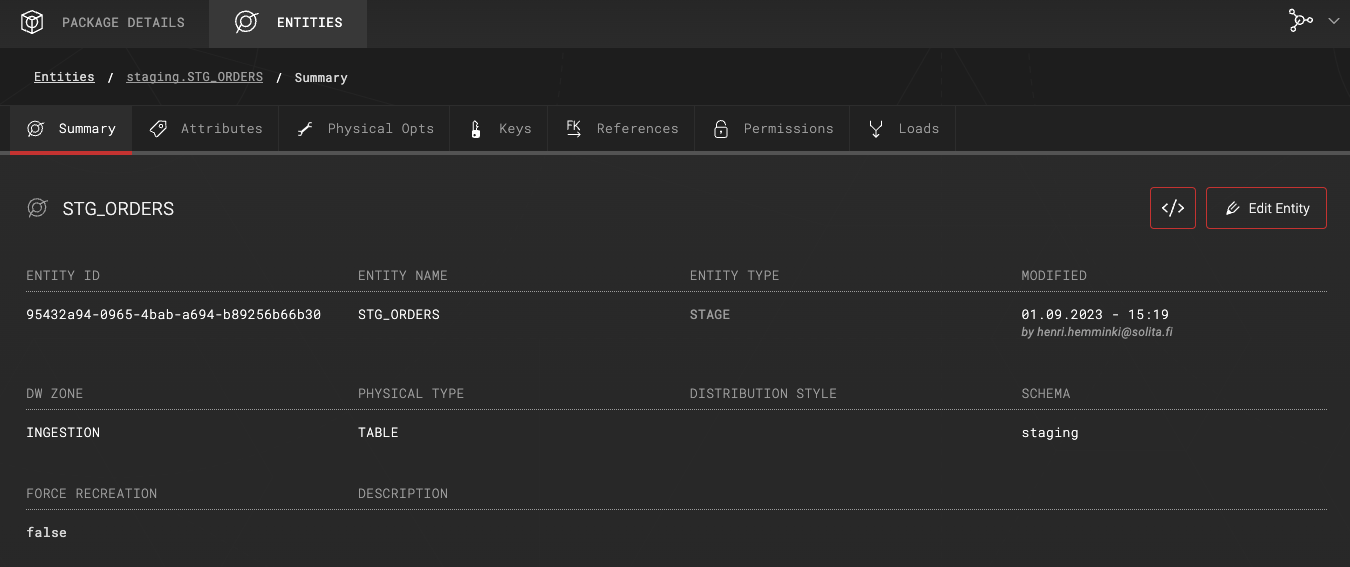
Creating a staging table for the raw data
In this example, a staging table is created on top of the raw data, and additional metadata attributes are added to support downstream processing. Depending on your use case, this staging entity can be implemented either as a physical table or as a view, especially if the raw data is already persisted in the target database.
Alternatively, this additional staging layer could be skipped completely, and the raw data entity could be mapped directly into downstream data warehouse tables. This approach may be suitable when no additional preprocessing or enrichment is needed.
Entity definition of the staging table:
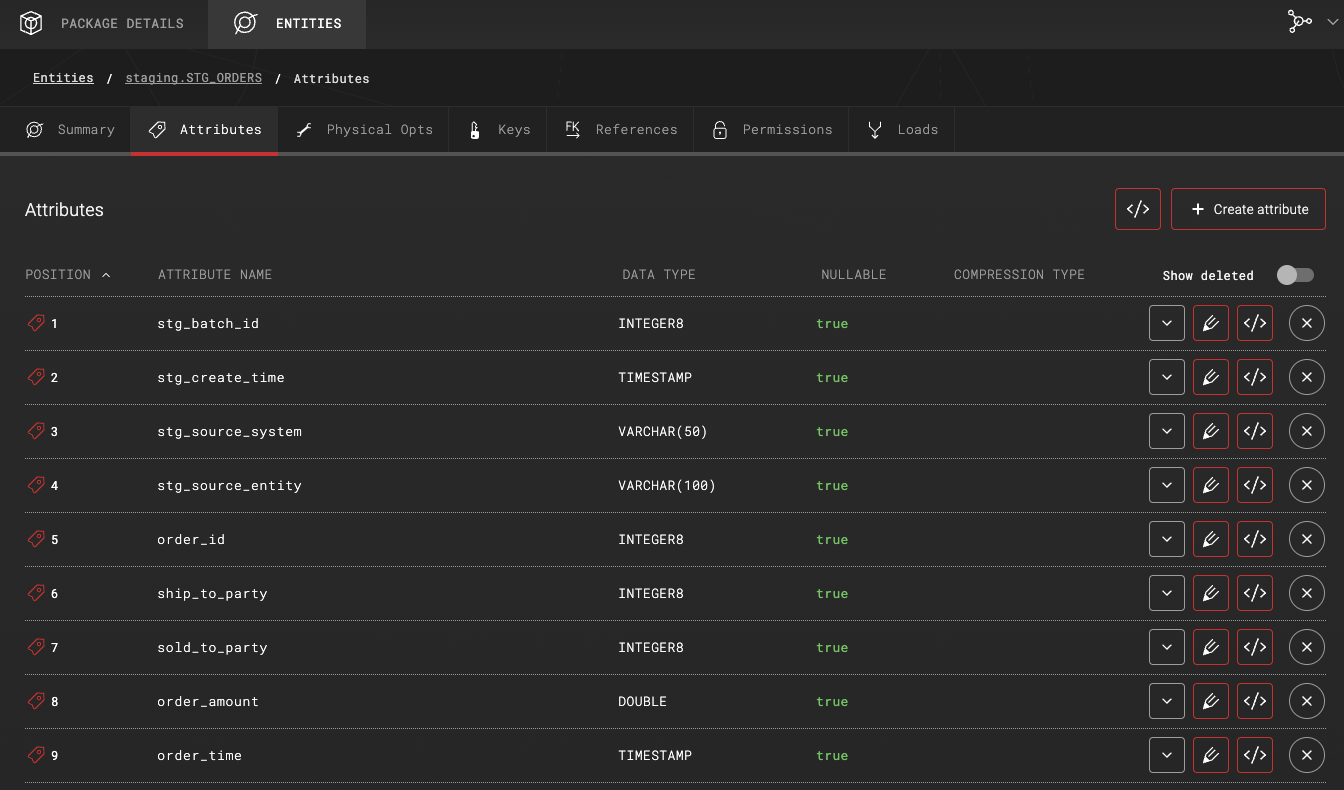
The entity contains automatically added default staging metadata attributes and mapped attributes from the source entity:
Generated load SQL:
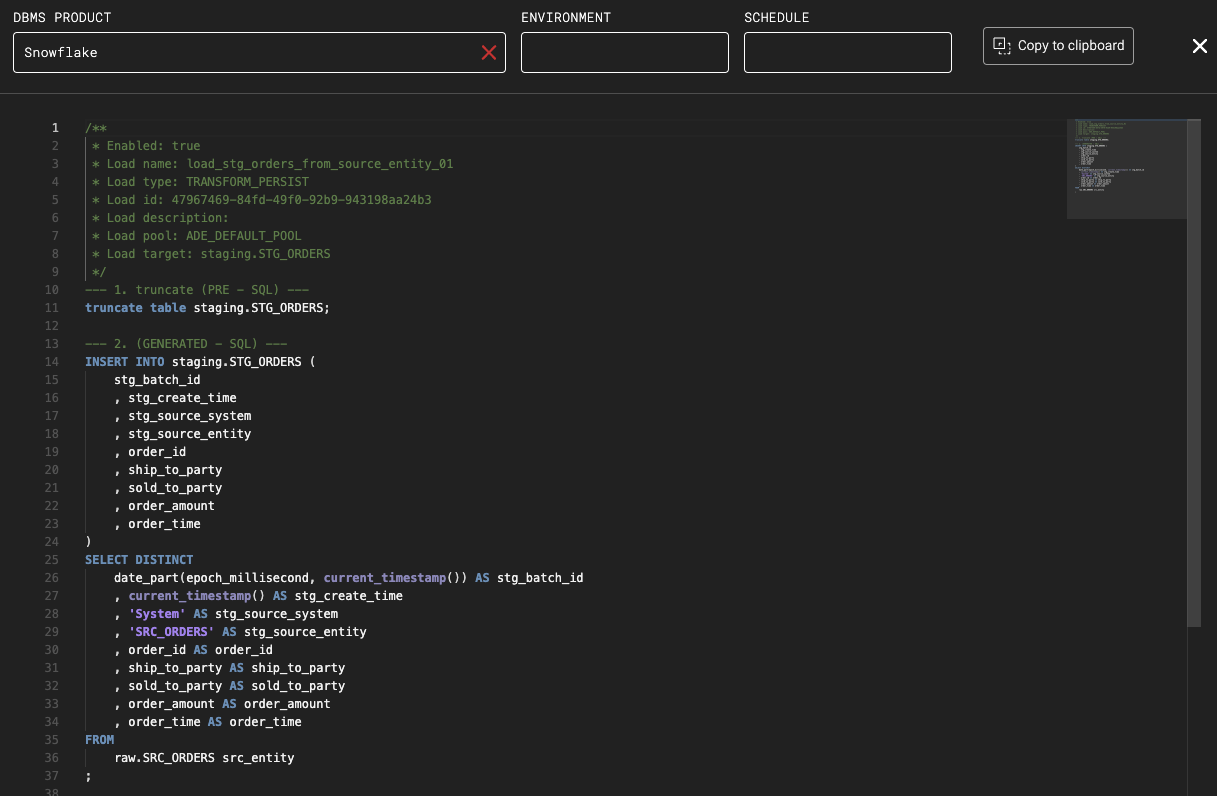
The truncate step has been added in the load definition as an additional PRE load step.
Transformations can be applied in the entity mapping as usual and variables used to e.g. populate the metadata attributes.