Guide objective
This guide explains how you can use dynamic tables in Snowflake in conjunction with ADE.
Dynamic tables serve various roles in data pipelines. Use cases include:
-
De-duplication in the staging layer
-
Parsing semi-structured data
-
Automating incremental data loading
With ADE, dynamic tables can be created with Physical type DYNAMIC_TABLE. ADE’s rich set of metadata variables enable the generation of environment-specific dynamic tables tailored to your needs.
See also:
Using dynamic tables in a data warehouse
This guide is intended for instructional purposes. Apply with caution in production environments.
Example use case
This scenario demonstrates the integration of the following Snowflake tools:
-
Snowpipe: For ingesting data from cloud storage into a Snowflake table
-
Dynamic tables in the staging layer:
-
For de-duplicating raw events
-
For parsing nested structures in semi-structured data
-
-
Data Vault modeling orchestrated by ADE
-
Dynamic tables in the publish layer:
Used to incrementally load a fact table and an aggregated fact, enabling near real-time updates for analytics directly from the Data Vault.
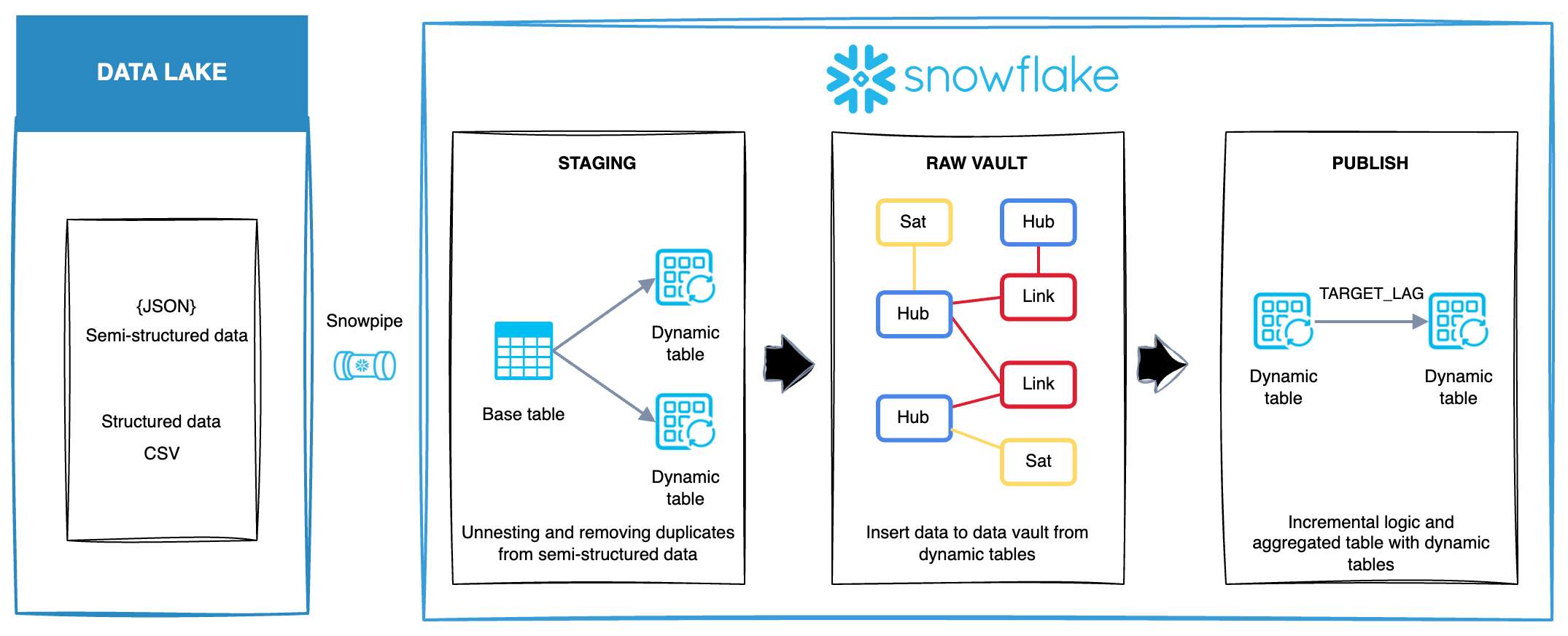
In Snowflake, both Snowpipe and dynamic tables are self-contained objects that manage data loading automatically, either through event-driven triggers or scheduled refreshes. While these objects do not require orchestration by ADE workflows for their execution, ADE coordinates the related processes, such as staging table creation, loading into the Data Vault, and populating the publish layer entities.
In this scenario, ADE is used to generate the DDL for both dynamic tables and Snowpipe. This approach centralizes code generation and supports a smooth integration between ADE and Snowflake features.
Creating a workflow for Snowpipe
In this example, a workflow named SF_SNOWPIPE_DDL is created in CONFIG_LOAD_SCHEDULES. This workflow includes the creation of Snowpipe in a single job.
A separate workflow can be created without a cron schedule. This means that the DDL can be executed as metadata in the Workflow Orhestration.
Creating a Snowpipe for data loading
An entity is created to handle example events about cash register data:
-
Physical type:
TABLE -
Entity type:
STAGE
Change tracking is enabled for the entity using the following option:
STORAGE.CHANGE_TRACKING: true
The following DDL is generated by ADE:
CREATE TABLE staging.STG_RAW_CASH_REGISTER_EVENT (
stg_file_name VARCHAR(200) NULL
, stg_create_time TIMESTAMP NULL
, cashier_id VARCHAR(36) NULL
, customer_id BIGINT NULL
, event_id VARCHAR(36) NULL
, items VARIANT NULL
, register_id VARCHAR(36) NULL
, status VARCHAR(50) NULL
, store_id VARCHAR(36) NULL
, timestamp TIMESTAMP NULL
, transaction_id VARCHAR(36) NULL
)
CHANGE_TRACKING = TRUE
COMMENT='STG_RAW_CASH_REGISTER_EVENT';
A load is configured for this entity, and the SF_SNOWPIPE_DDL workflow is attached. The following load step is created for the Snowpipe:
LOAD STEP: create_pipe_if_not_exists
CREATE PIPE IF NOT EXISTS <target_schema>.cash_register_pipe
AUTO_INGEST = TRUE
AS
COPY INTO <target_schema>.<target_entity_name>
FROM @<target_schema>.SNOWPIPE_STAGE/cash_register
MATCH_BY_COLUMN_NAME=CASE_INSENSITIVE
INCLUDE_METADATA = (stg_create_time=METADATA$START_SCAN_TIME, stg_file_name=METADATA$FILENAME)
FILE_FORMAT = (type = 'JSON', STRIP_OUTER_ARRAY = TRUE);
Now when the workflow SF_SNOWPIPE_DDL is executed, ADE load will create the Snowpipe.
Creating dynamic tables in staging layer
Two dynamic tables are created in this example:
-
A de-duplication table: Focused on selecting the latest record per event using a
QUALIFYclause. -
A semi-structured parsing table: For flattening nested
itemsfrom JSON data.QUALIFYclause is also used to de-duplicate the data.
The dynamic tables are created with the following options to ADE:
-
Physical type:
DYNAMIC_TABLE -
Entity type:
STAGE
Metadata variables used:
-
wh_dynamic-
A user-defined variable defined in CONFIG_ENVIRONMENT_VARIABLES.
-
A Dynamic Table is created to ADE during the deployment. See more in DYNAMIC_TABLE.
Both Dynamic Tables have DV_CASH_REGISTER workflow assigned to them. This workflow will be inherited to the downstream Data Vault entities.
Dynamic table with de-duplication
An entity mapping is created from the previously created staging table STG_RAW_CASH_REGISTER_EVENT. In the entity mapping, the relevant attributes are mapped from the source to the target entity. The entity mapping enables the use of variables target_entity_attribute_list_with_transform so that the dynamic table can be created based on metadata.
LOAD STEP: dynamic_table_sql_statement
SELECT <target_entity_attribute_list_with_transform>
FROM <source_entity_schema>.<source_entity_name>
QUALIFY ROW_NUMBER() OVER (PARTITION BY event_id ORDER BY timestamp desc) = 1
The following Physical Options are defined for the Dynamic tble:
REFRESH.DYNAMIC_TABLE_TARGET_LAG: 10 minutes
REFRESH.DYNAMIC_TABLE_WAREHOUSE: <wh_dynamic>
REFRESH.DYNAMIC_TABLE_REFRESH_MODE: INCREMENTAL
Resulting in the following ADE-generated DDL:
CREATE DYNAMIC TABLE staging.STG_CASH_REGISTER_EVENT_DYNAMIC (
stg_create_time TIMESTAMP COMMENT 'Internal Attribute'
, stg_source_system VARCHAR(50) COMMENT 'Internal Attribute'
, stg_source_entity VARCHAR(100) COMMENT 'Staging source entity'
, stg_file_name VARCHAR(100) COMMENT 'Staging file name'
, cashier_id VARCHAR(36)
, customer_id BIGINT
, event_id VARCHAR(36)
, register_id VARCHAR(36)
, status VARCHAR(50)
, store_id VARCHAR(36)
, timestamp TIMESTAMP
, transaction_id VARCHAR(36)
)
TARGET_LAG = '10 minutes'
WAREHOUSE = WH_DYNAMIC_TABLES_DEV
REFRESH_MODE = INCREMENTAL
AS
SELECT CURRENT_TIMESTAMP::timestamp_ntz AS stg_create_time
, 'CASH_REGISTER' AS stg_source_system
, 'STG_RAW_CASH_REGISTER_EVENT' AS stg_source_entity
, metadata$filename AS stg_file_name
, cashier_id AS cashier_id
, customer_id AS customer_id
, event_id AS event_id
, register_id AS register_id
, status AS status
, store_id AS store_id
, timestamp AS timestamp
, transaction_id AS transaction_id
FROM staging.STG_RAW_CASH_REGISTER_EVENT
QUALIFY ROW_NUMBER() OVER (PARTITION BY event_id ORDER BY timestamp desc) = 1;
Dynamic table with semi-structured data parsing
The same pattern is used as for the other dynamic table with similar variables. The only difference in this example is the usage of LATERAL FLATTEN to flatten the JSON structure:
LOAD STEP: dynamic_table_sql_statement
SELECT <target_entity_attribute_list_with_transform>
FROM <source_entity_schema>.<source_entity_name>,
LATERAL FLATTEN (input => items) it
QUALIFY ROW_NUMBER() OVER (PARTITION BY event_id, item_id order by timestamp desc) = 1
The following Physical Options are defined for the Dynamic tble:
REFRESH.DYNAMIC_TABLE_TARGET_LAG: 10 minutes
REFRESH.DYNAMIC_TABLE_WAREHOUSE: <wh_dynamic>
REFRESH.DYNAMIC_TABLE_REFRESH_MODE: INCREMENTAL
Resulting in the following ADE-generated DDL:
CREATE DYNAMIC TABLE staging.STG_CASH_REGISTER_EVENT_ITEMS_DYNAMIC (
stg_create_time TIMESTAMP COMMENT 'Internal Attribute'
, stg_source_system VARCHAR(50) COMMENT 'Internal Attribute'
, stg_source_entity VARCHAR(100) COMMENT 'Staging source entity'
, stg_file_name VARCHAR(100) COMMENT 'Staging file name'
, event_id VARCHAR(36)
, timestamp TIMESTAMP
, discount NUMBER(10,2)
, item_id VARCHAR(36)
, product_name VARCHAR(100)
, quantity BIGINT
, unit_price NUMBER(10,2)
)
TARGET_LAG = '10 minutes'
WAREHOUSE = WH_DYNAMIC_TABLES_DEV
REFRESH_MODE = INCREMENTAL
AS
SELECT CURRENT_TIMESTAMP::timestamp_ntz AS stg_create_time
, 'CASH_REGISTER' AS stg_source_system
, 'STG_RAW_CASH_REGISTER_EVENT' AS stg_source_entity
, metadata$filename AS stg_file_name
, event_id AS event_id
, timestamp AS timestamp
, it.value:"discount"::decimal(10,2) AS discount
, it.value:"item_id"::varchar(36) AS item_id
, it.value:"product_name"::varchar(100) AS product_name
, it.value:"quantity"::integer AS quantity
, it.value:"unit_price"::decimal(10,2) AS unit_price
FROM staging.STG_RAW_CASH_REGISTER_EVENT,
LATERAL FLATTEN (input => items) it
QUALIFY ROW_NUMBER() OVER (PARTITION BY event_id, item_id order by timestamp desc) = 1;
Creating the data warehousing layer with Data Vault
In this scenario, the data warehouse is implemented using Data Vault modeling. Since all the metadata exists in ADE, the Data Vault can be built on top of the dynamic tables.
For all the Data Vault tables, the change tracking is enabled:
STORAGE.CHANGE_TRACKING: true
Enabling Change Tracking on all source tables used by Dynamic Tables is mandatory in ADE. If Change Tracking is not enabled for every source table, the deployment of the Dynamic Table will fail.
Dynamic tables are efficient in a multitude of use cases, however, Data Vault is currently not one of them. Since the primary objective of Data Vault is to provide comprehensive historical tracking of data, dynamic tables are not well-suited for this purpose at present.
Workflow DV_CASH_REGISTER is inherited to the Data Vault objects from the Dynamic Tables created previously. Dynamic tables are automatically updated every 10 minutes and remain up to date. However, they are only refreshed when new data is available.
Creating the publish layer with dynamic tables
Creating a dynamic fact table
On top of Data Vault, a fact table F_DYNAMIC_SALES_ITEM is created. For this entity, the following options are used:
-
Physical type:
DYNAMIC_TABLE -
Entity type:
FACT
The attributes are added based on the SQL query by using “Import from data source” functionality. The workflow DV_CASH_REGISTER is inherited from the Data Vault objects.
In the Dynamic table, the following Physical options were set:
-
TARGET_LAGis set toDOWNSTREAMto update along with the downstream entity-
REFRESH.DYNAMIC_TABLE_TARGET_LAG: 10 minutes
-
-
REFRESH_MODEasINCREMENTALto update the fact table incrementally-
REFRESH.DYNAMIC_TABLE_REFRESH_MODE: INCREMENTAL
-
-
Variable
wh_dynamicwas used, as specified in earlier examples.-
REFRESH.DYNAMIC_TABLE_WAREHOUSE: <wh_dynamic>
-
LOAD STEP: dynamic_table_sql_statement
select
lci.dv_id_cash_register_event as event_id,
lsa.dv_id_customer_master as customer_id,
lc.dv_id_store as store_id,
lcis.item_id,
lcis.quantity,
lcis.unit_price,
lcis.discount,
lcis.quantity * lcis.unit_price - lcis.discount as line_item_total_amount
from rdv.l_cash_register_event_item lci
join rdv.sts_cash_register_event_item_c lcistst on lci.dv_id = lcistst.dv_id and lcistst.status = 1
join rdv.s_cash_register_event_item_c lcis on lci.dv_id = lcis.dv_id
join rdv.h_cash_register_event hc on lci.dv_id_cash_register_event = hc.dv_id
join rdv.l_cash_register_event lc on hc.dv_id = lc.dv_id_event
join rdv.l_sa_retail_customer lsa on lc.dv_id_customer = lsa.dv_id_customer_master
union all
select
loi.dv_id as event_id,
lsa.dv_id_customer_master as customer_id,
'1' as store_id,
loi.dv_id_order_item as item_id,
soec.quantity,
soec.price,
0 as discount,
soec.quantity * soec.price as line_item_total_amount
from rdv.l_order_item loi
join rdv.sts_order_item_c lois on loi.dv_id = lois.dv_id and lois.status = 1
join rdv.h_order_item hoi on loi.dv_id_order_item = hoi.dv_id
join rdv.s_order_item_erp_c soec on hoi.dv_id = soec.dv_id
join rdv.h_order ho on loi.dv_id_order = ho.dv_id
join rdv.l_order_customer loc on ho.dv_id = loc.dv_id_order
join rdv.l_sa_retail_customer lsa on loc.dv_id_customer = lsa.dv_id_customer_surrogate;
Creating an aggregated dynamic table
On top of this fact table, an aggregated fact F_DYNAMIC_SALES_AGGREGATE is created.
In the Dynamic table, the following Physical options were set:
-
TARGET_LAG is set to 30 minutes
-
REFRESH.DYNAMIC_TABLE_TARGET_LAG: 30 minutes
-
-
Variable
wh_dynamicis used for the warehouse.-
REFRESH.DYNAMIC_TABLE_WAREHOUSE: <wh_dynamic>
-
LOAD STEP: dynamic_table_sql_statement
SELECT
<target_entity_attribute_list_with_transform>
FROM
<source_entity_schema>.<source_entity_name>
GROUP BY ALL
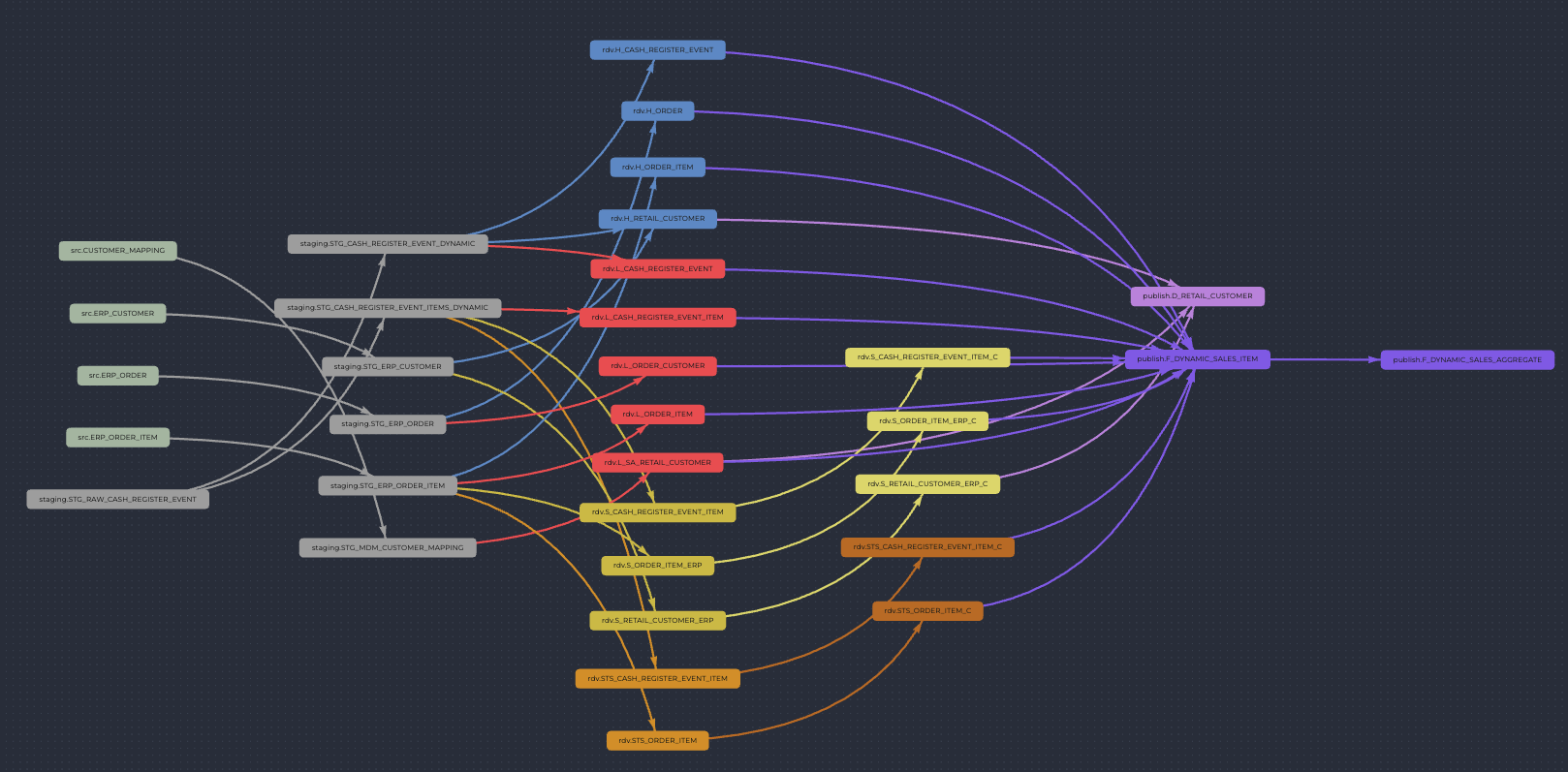
Data lineage of the whole scenario
The following data lineage was created in this scenario, it contains both dynamic tables and regular base tables in Snowflake: