In this guide, ADE Notifier application is explained in detail.
Notifier application is created to customer cloud and it is not part of Agile Data Engine -product.
Pre-requisites
Notifier application checklist
-
Set-up Notifier application infrastructure with static IP address.
-
Request from ADE support portal to allow the IP address to communicate with Notify API.
-
Add Notify API credentials to a safe place in the cloud (secrets manager, key vault or similar).
-
Test functionality with example file and check ADE Notify API Swagger.
Needed expertise to setup Notifier application
To set up Notifier application it needs cloud expertise to set up the required infrastructure.
Cloud expertise needed to set up the infrastructure:
-
Depending on the customer environment, either AWS, Azure or GCP knowledge
-
Infrastructure as code expertise in either AWS CDK, Terraform, Bicep or similar
-
Depending on the chosen cloud platform, either some programming knowledge (Python etc.) or data integration product knowledge (Azure Data Factory or similar)
Notifier application
Components
The common components in the Notifier application are:
-
Data bucket in cloud storage
-
Event notifications from data bucket to target queue
-
Function to process events and send those to Notify API
-
Static IP address
Example services needed per cloud:
Notifier architecture
The following diagram is used to explain each component in detail. The parts are:
-
Cloud Storage
-
File events
-
Notifier application
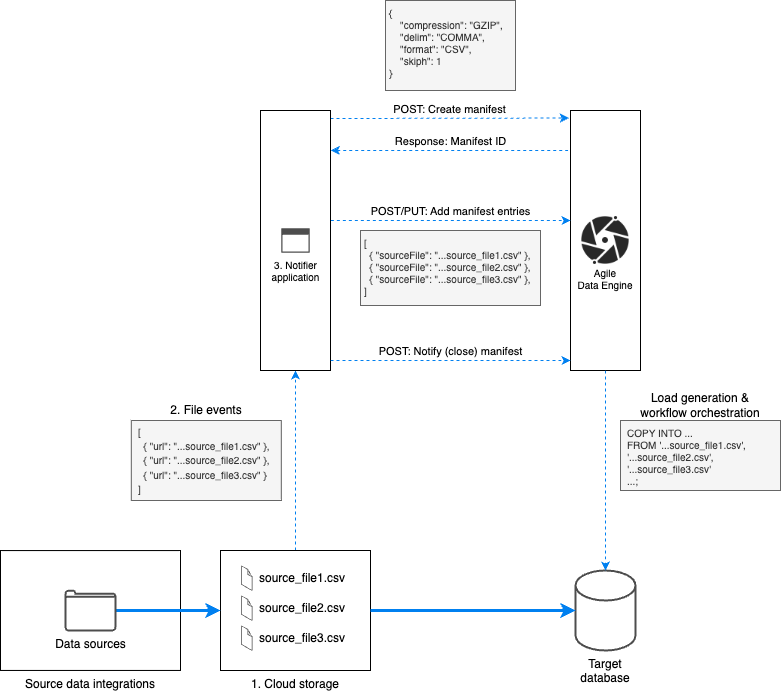
1. Cloud storage
Below are recommended practices to cloud storage, when using ADE Notifier.
Partitioning
It is recommended to use partitioning to keep data bucket in order:
# Partitioning
<source_system>/<source_entity>/<yyyy>/<mm>/<dd>/<file>
# Example:
system/entity/2023/03/02/file_name.csv.gz
File naming conventions
These are the recommended file-naming conventions:
-
Using ADE Private edition naming conventions for single files or manifest files.
-
These file naming conventions are still valid in SaaS edition and project can use those if needed
-
-
In ADE SaaS edition, there isn’t any hard rules for file naming, but there are some recommendations:
-
File format and compression specified in name
-
ADE source entity in file name or folder
-
Timestamp or epoch in the file name
-
Examples:
# File naming according to ADE Private edition
digitraffic/locations_latest/2023/03/02/table.locations_latest.1694496001640.batch.1694496001600.fullscanned.true.skiph.1.delim.semicolon.csv.gz
# File naming with recommended partitioning, but free file naming
digitraffic/metadata_vessels/2023/03/02/metadata_vessels_20230302_000048.json.gz
2. File events
Events from new files should be sent to queue for temporary storage. It is good practice to add dead-letter handling for events that can’t be processed.
3. Notifier application
Notifier application is, in practice:
-
Serverless function in the cloud, which makes API calls to Notify API
-
Is custom-coded. There are templates available in Github.
Notifier approaches
The following decision-tree can be used to explain different notifier approaches.
This decision-tree explains the generic flow of different Notifier approaches. Special cases and customizations may exist due to differences in cloud vendor services and different architectural decisions.
.png?cb=419b29da80d8b785649dece12aef3479)
|
Option |
Solution description |
Pros |
Cons |
|---|---|---|---|
|
1 |
Events are persisted to a database or cloud storage for later processing. Notifier application is invoked via schedule. In this case, multiple entries are batched to a single manifest to enable robust data ingestion. |
|
|
|
2 |
Notifier application reads events from queue based on schedule. Multiple entries are batched to a single manifest to enable robust data ingestion. |
|
|
|
3 |
For each event sent to queue, notifier application is invoked. Single file manifests are done and notified. |
|
|
|
4 |
For each event sent to queue, notifier application is invoked. Notifier application checks from Notify API, if there are existing manifests for the event. If there is, it will add event to existing manifest. If there isn’t, Notifier will create a new manifest. Separate scheduling is done for notifying (closing) manifests. |
|
|
Customer solution can follow any of the provided options or have a mix of the options. Usually there is a mix of these options, if there are data sources with different velocity. For example relational database sources which are extracted once a day and near-realtime flows with data coming every 5 minutes.
Mapping file events to ADE source system and source entity
To map file events to correct source system and source entity in ADE, as specified in ADE Notifier concepts, there are a couple of options.
-
Option 1. Use configuration files.
-
Configure properties of file events, such as:
-
What file maps to what source entity?
-
What is the format, compression and delimiter of the file?
-
-
Configuration file can be stored in version control, cloud storage or database, depending on the chosen Notifier approach.
-
Configuration file is good option when files names can be anything.
-
-
Option 2. Use naming conventions as in ADE Private Edition.
-
File properties, such as format, delimiter, number of header lines to skip and so on are stored in file names.
-
Source system and source entity can be specified in file path
<source_system>/<source_entity>. -
In this case, there is no need for separete configuration file.
-
Using Run ID logic
Run ID logic related to Notifier application, as you send Run ID:s to ADE through Notify API. Run ID:s can be sent in batch-field of manifest or manifest entry.
On high level, Run ID:s can be added:
-
On manifest level
-
Option 1: send Run ID in manifest header to Notify API with attribute batch. With this option, the same batch value needs to be in your data file as a column.
-
Option 2: let ADE generate Run ID on manifest level. Do not send batch information in manifest header or row level. Use manifestrunid variable in ADE file loads, if target database supports transforming data during data loading. If target database does not support it, see option 1.
-
-
On manifest entry level:
-
Within same manifest, you can add entries which all have different batch values
-
See example from Run ID guide.
-
For more detailed look into Run ID:s, see Using Run ID logic -guide.
Network configuration
Notifier application needs to have a static IP address so it can be added to allowed IP list in ADE. To have a static IP address for the application, there are different requirements per cloud vendor.
Network infrastructure may vary due to the cloud governance of customer cloud. Static, public facing IP address is the requirement from network configuration.
Reference architectures
Below you can find some reference architectures about Notifier setups in different clouds.