Guide objective
This guide helps you understand how to implement load steps to unload data into cloud storage.
Unloading data from the data warehouse to cloud storage is a common use case in cloud data warehousing. If your target database supports unloading data with an SQL statement, it is possible to design and orchestrate unloads with Agile Data Engine.
Snowflake
In Snowflake, you can unload data to cloud storage by using the COPY INTO command with a storage integration providing authentication to the target cloud storage and a stage object defining the cloud storage location.
With ADE, unloading from Snowflake to cloud storage is easy with load steps.
See also:
Examples
The examples use environment-specific Snowflake stages. Environment-specific values can be assigned in the CONFIG_ENVIRONMENT_VARIABLES configuration package, for example:
{
"environmentName": "DEV",
"variableName": "stage_name",
"variableValue": "@schemaname.stagename"
},
{
"environmentName": "TEST",
"variableName": "stage_name",
"variableValue": "@schemaname.stagename"
},
{
"environmentName": "PROD",
"variableName": "stage_name",
"variableValue": "@schemaname.stagename"
}
Modify naming as needed and replace variable values in the example with correct values from your environments. Environment variables should be used if stage objects vary between different environments. Here the variable is called stage_name and it can be referenced in load steps with <stage_name>.
Both examples have an F_SALES table where a load is created with load type TRANSFORM_PERSIST. The load has the following load steps:
1. LOAD STEP NAME: truncate - Target table F_SALES is truncated.
2. LOAD STEP NAME: insert - Target table F_SALES is populated with an INSERT statement.
Unload steps can be defined either as load steps in existing entities, or separated into their own entities. Note that you can use physical type METADATA_ONLY when defining separate entities for e.g. collecting unload steps into one place. Consider which option is best for your use case and easiest to maintain.
COPY INTO command for unloading data into cloud storage
In this example, we will define a COPY INTO command as a load step that unloads data into cloud storage.
3. LOAD STEP NAME: unload_to_s3
With the following SQL:
COPY INTO <stage_name>/<target_entity_name>/
FROM (SELECT * FROM <target_schema>.<target_entity_name>)
FILE_FORMAT = (
TYPE = CSV
COMPRESSION = 'GZIP'
RECORD_DELIMITER = '\n'
FIELD_DELIMITER = '|'
FIELD_OPTIONALLY_ENCLOSED_BY = '"' NULL_IF = '')
OVERWRITE = TRUE
SINGLE = TRUE
HEADER = TRUE;
This example uses the environment variable stage_name that we defined above, and built-in ADE variables target_schema and target_entity_name.
Load steps as seen in ADE:
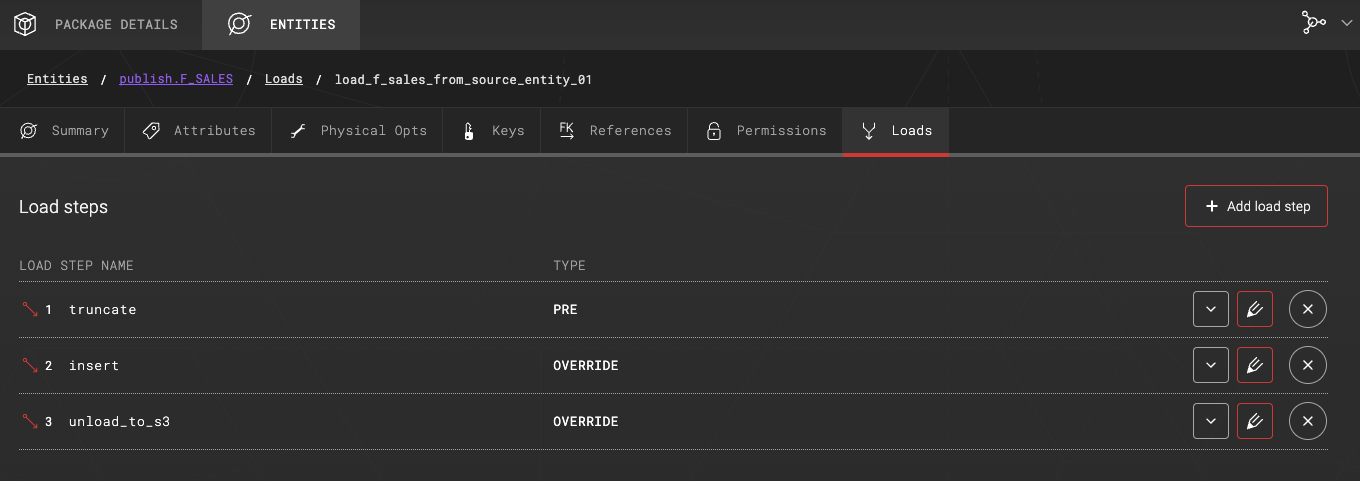
This example mixes load step types PRE and OVERRIDE. Note that if you are using automatic load generation, define the unload step with type POST and it will be executed after the automatically generated steps. OVERRIDE steps override automatically generated logic and will be executed in the defined order.
COPY INTO command with dynamic file path naming
In this example, we will define the data unload to cloud storage as a procedure which runs the COPY INTO command with dynamic file path naming. This allows more flexibility on how the files are named and partitioned (foldered) in the cloud storage.
-- Naming
<entity_name>/<YYYY>/<MM>/<DD>/<entity_name>_<timemillis>.csv.gz
-- Example file
f_sales/2023/06/07/f_sales_1686117085610.csv.gz
This example is implemented as a Snowflake procedure. The same logic could be implemented also e.g. by defining the COPY INTO statement as a Snowflake variable with SET and executing it with EXECUTE IMMEDIATE.
Define the following load steps:
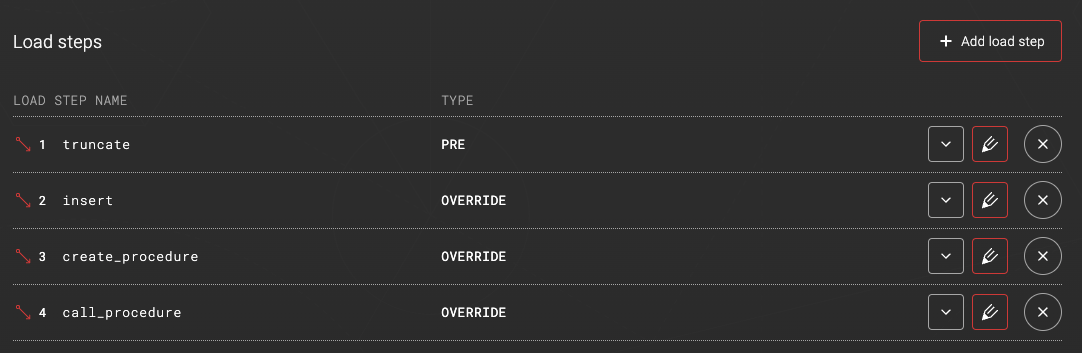
3. LOAD STEP NAME: create_procedure
With the procedure definition statement:
CREATE OR REPLACE PROCEDURE <target_schema>.copy_data_to_cloud_storage()
RETURNS TABLE()
LANGUAGE SQL
EXECUTE AS CALLER
AS
$$
DECLARE
partition VARCHAR;
stage VARCHAR;
unload_command VARCHAR;
full_path VARCHAR;
entity VARCHAR;
timemillis INTEGER;
file_name VARCHAR;
rs RESULTSET;
BEGIN
partition := (SELECT TO_CHAR(CURRENT_DATE, 'YYYY/MM/DD'));
stage := '<stage_name>';
entity := (SELECT lower('<target_entity_name>'));
full_path := stage::VARCHAR || '/' || entity || '/' || partition::VARCHAR || '/';
timemillis := (SELECT date_part(EPOCH_MILLISECOND, current_timestamp));
file_name := entity || '_' || timemillis || '.csv.gz';
unload_command := 'copy into ' || full_path::VARCHAR || file_name || ' ' ||
'from (select * from <target_schema>.<target_entity_name>) file_format = ' ||
'(type = csv compression = \'gzip\' record_delimiter = \'\\n\' field_delimiter = \'|\' ' ||
'field_optionally_enclosed_by = \'\"\' null_if = \'\') ' ||
'overwrite = false single = true header = true;';
rs := (EXECUTE IMMEDIATE :unload_command);
RETURN TABLE(rs);
END;
$$;
4. LOAD STEP NAME: call_procedure
With the procedure call statement that will unload the data from Snowflake to cloud storage:
CALL <target_schema>.copy_data_to_cloud_storage();
This example uses the environment variable stage_name that we defined above, and built-in ADE variables target_schema and target_entity_name.
Load steps as seen in ADE:
Creating a template
If unloading is needed in multiple entities, it is possible to create a template from the example load steps.
Example package
An example ADE package of this implementation is available in GitHub.
BigQuery
In BigQuery, you can unload data to cloud storage by using EXPORT DATA.
With ADE, unloading from BigQuery to cloud storage is easy with load steps.
See also:
Examples
In the examples, environment specific buckets are used. Environment specific values can be assigned in the CONFIG_ENVIRONMENT_VARIABLES configuration package, for example:
{
"environmentName": "DEV",
"variableName": "bq_unload_bucket",
"variableValue": "bucket-name-here"
},
{
"environmentName": "TEST",
"variableName": "bq_unload_bucket",
"variableValue": "bucket-name-here"
},
{
"environmentName": "PROD",
"variableName": "bq_unload_bucket",
"variableValue": "bucket-name-here"
}
Modify naming as needed and replace variable values in the example with correct values from your environments. Environment variables should be used if stage objects vary between different environments. Here the variable is called bq_unload_bucket and it can be referenced in load steps with <bq_unload_bucket>.
The example has an F_SALES table where a load is created with load type TRANSFORM_PERSIST. The load has the following load steps:
1. LOAD STEP NAME: truncate - Target table F_SALES is truncated.
2. LOAD STEP NAME: insert - Target table F_SALES is populated with an INSERT statement.
EXPORT DATA command for unloading data into cloud storage
In this example, unloading data to cloud storage with the EXPORT DATA command is defined as an ADE load step.
Data is exported to cloud storage with dynamic naming:
-- Naming
<entity_name>/<YYYY>/<MM>/<DD>/<files>.csv.gz
-- Example file
f_sales/2023/08/23/000000000000.csv.gz
Define the following load step:
3. LOAD STEP NAME: export_data
With the following SQL:
DECLARE custom_uri STRING DEFAULT (
SELECT lower('gs://<bq_unload_bucket>/<target_entity_name>/') ||
FORMAT_DATE('%G/%m/%d', current_timestamp()) || '/*.csv');
EXPORT DATA
OPTIONS(
uri=(custom_uri),
format='CSV',
overwrite=true,
header=true,
field_delimiter=';',
compression='gzip') AS
SELECT *
FROM <target_schema>.<target_entity_name>
This example uses the environment variable bq_unload_bucket that we defined above, and built-in ADE variables target_schema and target_entity_name.
Load steps as seen in ADE:
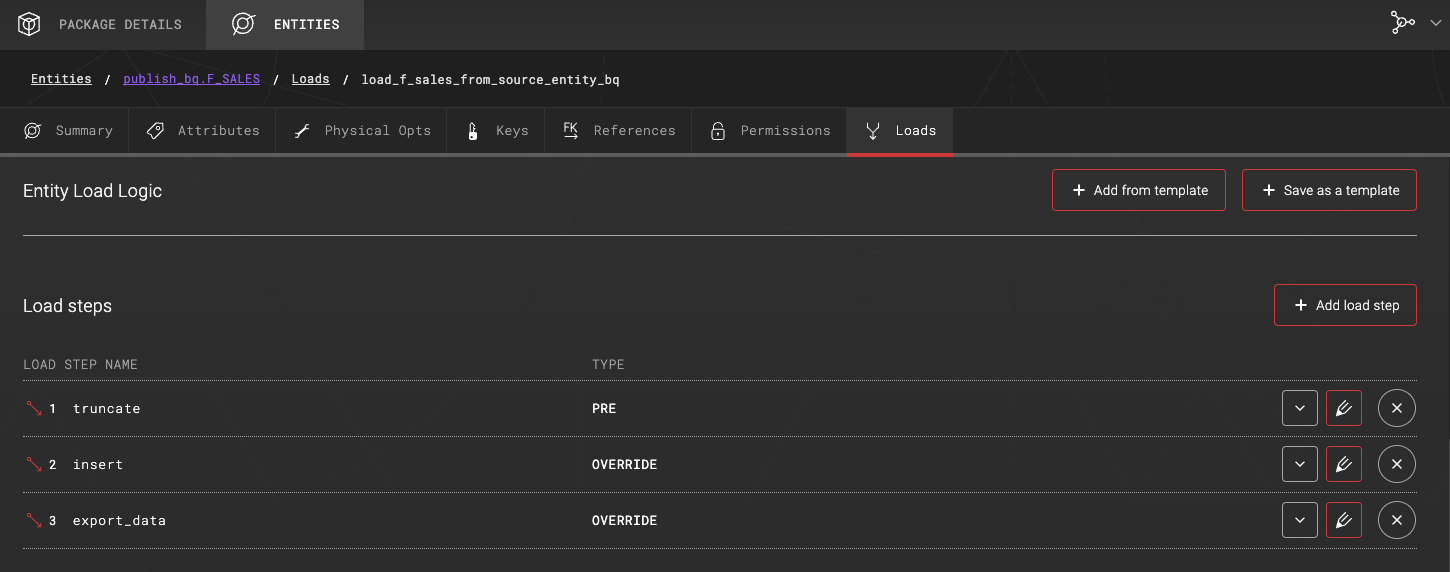
Unload steps can be defined either as load steps in existing entities, or separated into their own entities. Note that you can use physical type METADATA_ONLY when defining separate entities for e.g. collecting unload steps into one place. Consider which option is best for your use case and easiest to maintain.
Creating a template
If unloading is needed in multiple entities, it is possible to create a template from the example load steps.